







II. LES INFRASTRUCTURES DU NUMÉRIQUE
À l'image du niveau virtuel des échanges humains, l'échange numérique présente une structure globale.
A. INFRASTRUCTURES DE SERVICES MUTUALISÉS POUR LES ÉCHANGES NUMÉRIQUES
1. Infrastructure de noms de domaine (DNS)
C'est l'évolution croissante de systèmes à configurer puis à tenir à jour qui a suscité la mise à disposition d'un service centralisé, le DNS . L'infrastructure DNS est quasi publique, fédérée à destination des usagers de l'Internet par des institutions ou des gouvernements.
L'infrastructure globale repose sur une architecture client/serveur numérique au sein de laquelle les serveurs sont organisés de façon hiérarchique.
Le nommage consiste à juxtaposer le nom de la ressource représentant chaque niveau de la hiérarchie, le plus bas dans la hiérarchie.
Le principe général est que le client émet une requête vers un serveur de proximité afin d'obtenir le nom de domaine résultant de la résolution, des serveurs enfants aux serveurs racines ou root . Ces derniers constituent en quelque sorte la charpente du DNS mondial, ils sont au nombre de treize environ, hébergés aux États-Unis d'Amérique et sous le contrôle de l' Internet Assigned Numbers Authority ( IANA ).
Sur le plan opérationnel, le DNS permet à la fois une fonction technique pour communiquer entre domaines et serveurs interconnectés via des requêtes et une fonction indirectement commerciale grâce aux fonctions de recherche et priorisation d'un site sur le nom de domaine.
L'infrastructure de noms de domaine ou Domain Name System ( DNS ) permet la conversion d'une adresse IP en nom ou domaine et inversement. Étant donné qu'il est plus aisé de saisir des adresses de noms comme « www.france.gouv » que des adresses de nombres comme une adresse IP « 1.2.3.4 », une première étape a consisté à configurer sur chaque poste de travail une association IP /nom de domaine .
Schéma n° 29 : Infrastructure de noms de domaine ( DNS)

Source : OPECST
Le DNS s'est transformé en un modèle d'affaire pour certains acteurs qui, dans le but d'une revente spéculative, se sont mis à acquérir des noms de domaine d'entreprises de réputation élevée.
|
« Le fait que les noms de domaines soient attribués par une association américaine ne pose pas de problème particulier à Total . Les domaines intéressants ont été réservés : le Total.com, le total. »
M. Patrick Hereng
|
2. Infrastructure de routage et de messagerie
La messagerie électronique permet de véhiculer des courriers à partir de services mutualisés ou/et privés en apportant un certain nombre de fonctions tirées de celles proposées par le courrier postal : accusé de réception, etc. Les avantages sont l'accélération dans les modes de communications et, par là-même, dans les cycles de décision.
L'infrastructure de messagerie est une architecture client/serveur numérique composée, d'une part, d'un réseau d'accès et, d'autre part, d'une infrastructure affectée au routage des messages.
Schéma n° 30 : Infrastructure de messagerie
Source : OPECST
3. Infrastructure de navigation : les moteurs de recherche
Le principe d'information est le principe fondamental de l'Internet où l'outil incontournable pour l'usager est la recherche et la classification de l'information.
L'infrastructure du web repose sur trois éléments :
- le robot également appelé crowler ou spider qui collecte toutes les pages ;
- l'index qui renferme tous les mots de toutes les pages collectées par le robot, puis, qui le relie aux URLs des pages dont ils proviennent, repérées à l'aide des noms de domaines DNS ;
- l'interface pour émettre la requête et en recevoir les résultats.
L'infrastructure du web repose sur une architecture client/serveur où le navigateur web est client et les serveurs web sont de deux types : le serveur de contenu qui détient l'information et la rend disponible et le serveur de recherche qui détient l'index général avec l'algorithme de classement des réponses.
• Le serveur de recherche
Le processus d'une recherche numérique se déroule en sept étapes :
1) l'usager lance une requête ;
2) le moteur de recherche interroge l'index à l'aide des mots de la requête ;
3) l'index pointe les pages qui contiennent les mots-clés ;
4) l'index classe les pages dans un ordre déterminé par un algorithme spécifique : Search Engine Result Pages ( SERP ) ;
5) l'index prépare la liste de réponses : titre, extrait, URL , et la transmet à l'usager grâce aux protocoles HTTP et HTTPS ;
6) l'usager clique sur le « titre » de la page et se connecte sur le site concerné ;
7) l'index apprend le lien entre la requête initiale et la réponse choisie à l'étape 6, ci-dessus, pour améliorer la pertinence de la prochaine recherche .
• La description de la connaissance
Pour décrire une connaissance, le langage HyperText Markup Language ( HTML ) :
- décompose la connaissance diffusée en pages de contenu : la page HTML est l'entité élémentaire localisée et identifiée de façon unique par son URL ;
- relie les pages HTML entre elles : un peu comme le principe du « fil d'Ariane », la connaissance est structurée en réseau .
Une fois l'information trouvée sur une page principale, l'index et les liens suivis vont conduire l'usager vers une information de plus en plus précise.
Les protocoles HyperText Transfer Protocol ( HTTP ) et HyperText Transfer Protocol Secure ( HTTPS ) sont les protocoles pour transporter les liens et pages au sein de l'architecture web .
Cette capacité repose sur l'organisation documentaire des serveurs web et en particulier du webmaster . Chaque site web possède une tête de liste, souvent appelée « index » qui oriente le visiteur de pages en pages. L'intérêt de ce modèle est la taille très petite d'une page html qui permet ainsi d'envisager des accès de masse.
• Le témoin de connexion ou cookie
Lors d'une visite sur un site web (lors de la phase 6 de la recherche), les serveurs incorporent dans leur protocole plusieurs capacités :
- lire les informations transportées dans le protocole HTTP qui rendent unique la source de la requête : tel usager. Il est également possible de noter son adresse IP , son nom de domaine de connexion, etc.
- relier ces informations à celles demandées à l'utilisateur : son nom de login , son mot de passe, et les autres informations données lors d'une inscription sur son site web ;
- le serveur peut également inclure dans le protocole la demande d'un fichier de connexion appelé cookie dans lequel les serveurs incorporent des informations comme les identifiants de session (temporaire), les heures de connexion et autres informations .
Ce petit fichier anodin le resterait s'il n'était pas utilisé à de nombreuses reprises :
- par les responsables de sites pour élaborer des profils dits de « user experience » ;
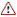 - par des
attaquants pour obtenir des numéros de session et s'insinuer dans le
flux légitime ;
- par des
attaquants pour obtenir des numéros de session et s'insinuer dans le
flux légitime ;
- pour toute autre utilisation.