







II. L'HISTOIRE DES TECHNOLOGIES D'INTELLIGENCE ARTIFICIELLE ET DE LEURS USAGES
A. DES TECHNOLOGIES NÉES AU MILIEU DU XXE SIÈCLE
1. La préhistoire de l'intelligence artificielle et sa présence dans les oeuvres de fiction
Les paragraphes suivants font le point sur les techniques d'intelligence artificielle et utilisent notamment les ouvrages cités, notamment la brochure de l'Académie des technologies de « dix questions sur l'intelligence artificielle et la technologie ».
De nombreuses incarnations d'intelligence artificielle ont jalonné notre histoire, qu'il s'agisse de mythes ou de projets imaginés par les écrivains et les scientifiques. Comme il a été vu, Jean-Claude Heudin et Michel de Pracontal leur ont consacré des ouvrages entiers 41 ( * ) . Bruce Buchanan a, quant à lui, rédigé un article sur l'histoire de l'intelligence artificielle qui revient également sur l'ensemble de ses précurseurs 42 ( * ) . Comme le relève Jean-Gabriel Ganascia, que vos rapporteurs ont pu rencontrer à plusieurs reprises, Homère a décrit, dans « L'Iliade », des servantes en or douées de raison : « Fabriquées par Héphaïstos, le dieu forgeron, elles ont, selon le poète, voix et force ; elles vaquent aux occupations quotidiennes à la perfection, car les immortels leur ont appris à travailler. Ce sont donc des robots, au sens étymologique de travailleurs artificiels ». Ovide dans ses « Métamorphoses » crée la figure de Galatée, statue d'ivoire sculptée par Pygmalion et à laquelle Vénus, déesse de l'amour, accepte de donner vie. Jean-Gabriel Ganascia rappelle également qu'il existait dès l'Égypte ancienne des statues articulées, animées par la vapeur et par le feu, qui hochaient la tête et bougeaient les bras, véritables ancêtres des automates. La Bible , par le Psaume 139:16, a fondé le mythe du Golem, cette créature d'argile humanoïde que l'on retrouve souvent dans la tradition cabalistique juive.
En 1495, en vue de festivités organisées à Milan, Léonard de Vinci imagine puis construit, bien que ce dernier point reste débattu, un « chevalier mécanique », sorte de robot automate revêtu d'une armure médiévale. Sa structure interne en bois, avec quelques parties en métal et en cuir, était actionnée par un système de poulies et de câbles.
Avec ses « animaux-machines », René Descartes proposa, quant à lui, dans la première moitié du XVII e siècle, de reproduire artificiellement les fonctions biologiques, y compris la communication et la locomotion. Blaise Pascal réfléchit à la création d'une machine à calculer. À la fin du XVII e siècle, Leibniz imagine ensuite une machine à calculer capable de raisonner. Il construit un prototype de machine à calculer en 1694.
Pendant le siècle des Lumières, le philosophe français Julien de la Mettrie anticipe le jour où les progrès de la technique permettront de créer un homme-machine tout entier, à l'âme et au corps artificiels. L'abbé Mical et Kratzenstein imaginent une machine à parler en 1780, bientôt construite par le baron Von Kempelen grâce à une cornemuse à tuyaux multiples, aujourd'hui propriété du « Deutsches Museum » de Munich.
Dès 1818, Mary Shelley publie son roman « Frankenstein ou le Prométhée moderne » , dans lequel elle imagine un savant capable de créer un être artificiel, le monstre Frankenstein.
Au milieu du XIX e siècle, George Boole appelle à mathématiser la logique, Charles Babbage conçoit l'ancêtre mécanique des ordinateurs d'aujourd'hui 43 ( * ) et l'économiste britannique William Stanley Jevons imagine des pianos mécaniques, capables de raisonner.
Jules Verne , dans son roman, La Maison à vapeur , paru en 1880 imagine un éléphant géant à vapeur capable de traverser l'Inde, sur terre, comme sur l'eau. Sa machine n'est cependant pas autonome.
Alors qu' Isaac Asimov affirmait qu' « on peut définir la science-fiction comme la branche de la littérature qui se soucie des réponses de l'être humain aux progrès de la science et de la technologie » , force est de constater que l'intelligence artificielle est un thème de science-fiction particulièrement fécond pour la littérature , le cinéma et les jeux vidéo . Laurence Devillers souligne cette réalité incontestable dans son livre Des robots et des hommes : mythes, fantasmes et réalité .
Les ouvrages d'Isaac Asimov lui-même, mais aussi d'Arthur C. Clarke, de Philip K. Dick ou de William Gibson l'illustrent, ainsi que le font, au cinéma, de 1927 à 2017 , les films « Metropolis », « 2001, l'Odyssée de l'espace », « Mondwest », « Les Rescapés du futur », « Le Cerveau d'acier », « Génération Proteus », « Blade runner », « Tron », « Terminator », « Matrix », « A.I. », « I, Robot », « Iron Man », « Wall-E », « Eva », « The Machine », « Transcendance », « Chappie », « Her », « Ex Machina » , ou, encore, cette année, « Ghost in the Shell » . Les thèmes de l' hostilité de l'intelligence artificielle ou des risques que cette dernière ferait courir à l'espèce humaine sont souvent au coeur de l'intrigue de ces oeuvres.
Récemment, des séries télévisées à succès comme « Person of interest », « Emma », « Westworld » ou, surtout, « Real Humans » et « Humans » ont également exploité ce sujet.
2. Les premières étapes de formation des technologies d'intelligence artificielle au XXe siècle, la notion d'algorithme et le débat sur la définition du concept d'intelligence artificielle
L'intelligence artificielle a fêté l'année dernière son soixantième anniversaire , puisqu'elle est inventée en tant que discipline et concept en 1956 dans un contexte que vos rapporteurs vont présenter dans les pages suivantes. Elle repose sur l'utilisation d' algorithmes , dont l'histoire est bien plus ancienne que celle de leurs usages en informatique.
Le mot algorithme est issu de la latinisation du nom du mathématicien Al-Khawarizmi , dont le titre d'un des ouvrages (« Abrégé du calcul par la restauration et la comparaison » ), écrit en arabe entre 813 et 833, et dont la seule copie est conservée à l'Université d'Oxford, visitée par vos rapporteurs, est également à l'origine du mot algèbre . Il est le premier à proposer des méthodes précises de résolution des équations du second degré, du type « ax² + bx + c =0 ».
La longue histoire des algorithmes est bien décrite par Serge Abiteboul et Gilles Dowek, dans leur ouvrage Le temps des algorithmes . Ils ont tous les deux été auditionnés par vos rapporteurs. Ils rappellent que les algorithmes sont utilisés depuis des milliers d'années , qu' Euclide a inventé en l'an 300 avant notre ère un algorithme de calcul du plus grand diviseur commun de deux nombres entiers et que la complexité de certains algorithmes récents est telle qu'ils peuvent être comparés à des cathédrales . Le domaine qui étudie les algorithmes est appelé l'algorithmique.
De manière résumée, un algorithme est un ensemble de séquences d'opérations. Il s'agit, de manière plus précise et rigoureuse, d'une suite finie et non ambiguë d'opérations ou d'instructions permettant, à l'aide d'entrées, de résoudre un problème ou d'obtenir un résultat, ces sorties étant réalisées selon un certain rendement 44 ( * ) . De nombreuses applications sont possibles, à commencer par l'informatique, le fonctionnement des ordinateurs, en particulier leurs systèmes d'exploitation, reposant sur des algorithmes. Les algorithmes peuvent, en effet, servir, comme le rappellent Serge Abiteboul et Gilles Dowek, à calculer , mais aussi à gérer des informations (comme le font les logiciels d'archivage par exemple), à analyser des données (comme le font les moteurs de recherche), à communiquer (comme le font les protocoles utilisés pour Internet par exemple), à traiter un signal (comme le font les appareils photo et les microphones numériques par exemple), à commander un robot (comme le font les systèmes d'analyse des capteurs utilisés pour les voitures autonomes par exemple), à fabriquer des biens (comme le font les « usines 4.0 » supervisées par des algorithmes par exemple) ou, encore, à modéliser simuler et prévoir (comme le font certains outils de météorologie, de sismologie, d'océanographie ou, encore, de planétologie par exemple).
L'informatique constitue un domaine d'application privilégié pour les algorithmes. Mais son histoire ne se confond pas avec celle de ces derniers. Il en est de même pour l'histoire de l'intelligence artificielle, bien que ces trois histoires soient liées. En effet, comme il sera vu plus loin, l'informatique traite plutôt de questions résolues par des algorithmes connus , alors que l'on applique le label d'« intelligence artificielle » à des applications permettant de résoudre des problèmes moins évidents.
Dès 1936, Alan Turing pose les fondements théoriques de l'informatique et introduit les concepts de programme et de programmation . Il imagine en effet, à ce moment, un modèle abstrait du fonctionnement d'un appareil doté d'une capacité élargie de calcul et de mémoire, en recourant à l'image d'un ruban infini muni d'une tête de lecture/écriture, qui sera appelé « machine de Turing », précurseur de l'ordinateur moderne. Puis, dans un article paru en 1950 45 ( * ) , il explore le problème de l'intelligence artificielle et propose une expérience maintenant connue sous le nom de « test de Turing » , qui est une tentative de définition à travers une épreuve d'un critère permettant de qualifier une machine de « consciente » 46 ( * ) . Il fait alors le pari que « d'ici à cinquante ans, il n'y aura plus moyen de distinguer les réponses données par un homme ou un ordinateur, et ce sur n'importe quel sujet ». Cette prophétie d'Alan Turing quant aux progrès connus en l'an 2000 ne s'est pas encore réalisée à ce jour.
De leur côté, les mathématiciens et neurologues Warren McCulloch et Walter Pitts écrivent dès 1943 un article intitulé « Un calculateur logique des idées immanentes dans l'activité nerveuse » 47 ( * ) dans lequel ils posent l'hypothèse que les neurones avec leurs deux états, activé ou non activé, pourraint permettre la construction d'une machine capable de procéder à des calculs logiques. Ils publièrent dès la fin des années 1950 des travaux plus aboutis sur les réseaux de neurones artificiels . C'est en 1957 que Frank Rosenblatt développe le Perceptron, première modélisation de réseau de neurones artificiels 48 ( * ) , à partir des travaux de McCulloch et Pitts. Ces derniers publient un article plus important que les autres en 1959 49 ( * ) et constituent donc un modèle simplifié de neurone biologique, communément appelé neurone formel . Leurs travaux démontrèrent que des réseaux de neurones formels simples pouvaient théoriquement réaliser des fonctions logiques, arithmétiques et symboliques complexes. Leur fonctionnement sera expliqué plus loin.
Trois ans plus tôt, en 1956, John McCarthy et Marvin Minsky ont organisé une école d'été à Dartmouth qui est considérée comme l'acte de naissance de l'intelligence artificielle , à la fois en tant que discipline et en tant que concept d' artificial intelligence .
Le concept a fait l'objet d'un débat et il est dit a posteriori que le choix du mot devrait beaucoup à la quête de visibilité de ce nouveau champ de recherche . Parler d'intelligence artificielle a pu apparaître comme plus séduisant que de parler des « sciences et des technologies du traitement de l'information » . L'anthropomorphisme essentialiste 50 ( * ) qui est exprimé par le choix du concept d'« intelligence artificielle » n'a sans doute pas contribué, selon vos rapporteurs, à apaiser les peurs suscitées par le projet prométhéen de construction d'une machine rivalisant avec l'intelligence humaine .
Cette conférence, soutenue par la fondation Rockfeller, par Nathan Rochester, alors directeur scientifique d'IBM, et par Claude Shannon, ingénieur, mathématicien et père des théories de l'information et de la communication, offre en effet à John McCarthy l'occasion de convaincre les participants d'accepter l'expression « intelligence artificielle » en tant qu'intitulé de ce domaine de recherche. La conférence affirme donc dès 1956 que « chaque aspect de l'apprentissage ou toute autre caractéristique de l'intelligence peut être si précisément décrit qu'une machine peut être conçue pour le simuler ». La rigueur pousse à observer que le projet n'est pas, en réalité, de construire une machine rivalisant avec l'homme mais de simuler telle ou telle tâche que l'on réserve à l'intelligence humaine.
Outre John McCarthy et Marvin Minsky, les participants , tels que Ray Solomonoff, Oliver Selfridge, Trenchard More, Arthur Samuel, Allen Newell et Herbert Simon, ayant posé comme conjecture que tout aspect de l'intelligence humaine peut être décrit de façon assez précise pour qu'une machine le reproduise en le simulant, discutent ensuite des possibilités de créer des programmes d'ordinateur qui se comportent intelligemment , c'est-à-dire qui résolvent des problèmes dont on ne connaît pas de solution algorithmique simple.
Dans les années suivantes, soutenus par l'agence américaine pour les projets de recherche avancée de défense du ministère de la Défense ( Defense Advanced Research Projects Agency ou DARPA), mais aussi par IBM, les chercheurs mettent au point de nouvelles techniques informatiques : le langage Lisp en 1958, l'un des plus anciens langages de programmation 51 ( * ) , le premier programme démontrant des théorèmes d'où est issue la notion d'heuristique (règle empirique utile permettant de réduire les chemins possibles mais sans aboutir nécessairement à une solution), une première idée des réseaux de neurones artificiels (le Perceptron, dont Marvin Minsky souligne les limites théoriques), un programme qui joue aux dames et apprend par apprentissage à jouer de mieux en mieux... Ces découvertes rendent les pères fondateurs de l'intelligence artificielle très optimistes .
En 1958, Herbert Simon et Allen Newell déclarent ainsi que « d'ici à dix ans un ordinateur sera le champion du monde des échecs » 52 ( * ) et « d'ici à dix ans, un ordinateur découvrira et résoudra un nouveau théorème mathématique majeur ».
En 1965, Herbert Simon assure que « des machines seront capables, d'ici à vingt ans, de faire tout travail que l'homme peut faire ». En 1967, Marvin Minsky estime que « dans une génération [...] le problème de la création d'une intelligence artificielle sera en grande partie résolu » , et en 1970 que « dans trois à huit ans nous aurons une machine avec l'intelligence générale d'un être humain ordinaire »
De même, le premier agent conversationnel (« chatbot » ou « bot ») est créé en 1966 par Joseph Weizenbaum et simule un psychothérapeute grâce à sa technologie de reconnaissance des formes. Il s'appelle « Eliza » et suscite un grand enthousiasme.
Mais ses capacités restent limitées , puisqu'il est incapable de vraiment répondre aux questions posées, se contentant de continuer à faire parler son interlocuteur, dans une logique de relance.
Capture d'écran d'un exemple de conversation avec Eliza

Source : Norbert Landsteiner https: //fr.slideshare.net/ashir233/eliza-4615
La représentation des connaissances, le langage objet, est au coeur de l'intelligence artificielle des années 1950 et 1960 et elle est ensuite mise au service de l'informatique, avec des résultats remarquables permettant les progrès connus vers les ordinateurs modernes. Ainsi que le remarque l'académicien des technologies Gérard Sabah, l'informatique classique traite traditionnellement de questions résolues par des algorithmes connus , alors que l'intelligence artificielle s'intéresse plutôt aux problèmes pour lesquels aucun algorithme satisfaisant n'existe encore .
Le paradoxe résultant de cette définition est le suivant : dès que le problème a été résolu par une technologie dite d'intelligence artificielle, l'activité correspondante n'est plus considérée comme une preuve d'intelligence de la machine . Les cas connus de résolutions de problèmes d'algèbre ou de capacité à jouer à des jeux (des jeux d'échecs par exemple) illustrent ce phénomène. Nick Bostrom explique ainsi que « beaucoup d'intelligence artificielle de pointe a filtré dans des applications générales, sans y être officiellement rattachée car dès que quelque chose devient suffisamment utile et commun, on lui retire l'étiquette d'intelligence artificielle ».
Les progrès en matière d'intelligence artificielle étant tangibles depuis les années 1950, les frontières de l'intelligence artificielle sont donc sans cesse repoussées et ce qui était appelé intelligence artificielle hier n'est donc plus nécessairement considéré comme tel aujourd'hui .
Vos rapporteurs observent que, dès l'origine, l'intelligence artificielle est bien une étiquette . Ce label recouvre en réalité des technologies diverses, dont ils ont voulu retracer la richesse et la diversité dans le présent rapport.
Vos rapporteurs ont, en effet, relevé dans leurs investigations que les outils d'intelligence artificielle sont très divers, ce qui traduit la variété des formes d'intelligence en général : elles vont de formes explicites (systèmes experts et raisonnements logiques et symboliques) à des formes plus implicites (réseaux de neurones et deep learning ).
3. « L'âge d'or » des approches symboliques et des raisonnements logiques dans les années 1960 a été suivi d'un premier « hiver de l'intelligence artificielle » dans les années 1970
« L'âge d'or » des approches symboliques et des raisonnements logiques se produit dans les années 1960 après la naissance de l'intelligence artificielle à Dartmouth. Recourant à des connaissances précises, telles que des logiques diverses ou des grammaires, ces formes d'intelligence sont dites explicites .
Il existe, ensuite, les diverses modalités de formalisme logique , soit sous la forme de logique classique , de logique floue , de logique modale ou de logique non monotone .
La logique mathématique peut représenter des connaissances 53 ( * ) et modéliser des raisonnements . Le principe de résolution permet d'automatiser ces raisonnements : pour démontrer une propriété, on montre que son contraire entraîne une contradiction avec ce qu'on sait déjà. La seule règle utilisée est celle du « détachement » ou modus ponens , figure du raisonnement logique concernant l'implication (exemple : « si p implique q et si p, alors q »). Cette méthode ne s'applique qu'à des cas simples, où la combinatoire n'est pas excessive. Fondé sur le même principe, le langage Prolog (acronyme de PROgrammation LOGique, qui permet de résoudre les problèmes par raisonnement à partir de règles de logique formelle) lève ces restrictions en permettant d'aborder des problèmes plus complexes.
Des difficultés subsistent pour traiter des connaissances vagues ou incomplètes . Devant ces limites, des extensions théoriques ont donné lieu à des logiques non classiques permettant d'exprimer plus d'éléments que dans la logique classique. Voulant étendre les possibilités de la logique classique, les logiques multivaluées gardent les mêmes concepts de base, hormis les valeurs de vérité, qui, selon les théories, varient de trois à un nombre infini de valeurs. La théorie des logiques floues étend ces logiques en considérant comme valeurs de vérité le sous-ensemble réel « [0,1] ». Elles permettent de traiter des informations incertaines (Jean viendra peut-être demain) ou imprécises (Anne et Brigitte ont à peu près le même âge).
Les logiques modales introduisent des notions comme la possibilité, la nécessité, l'impossibilité ou la contingence qui modulent les formules de la logique classique. La notion de vérité devient relative à un instant donné ou à un individu. On distingue ainsi ce qui est accidentellement vrai (contingence : Strasbourg est en France) de ce qui ne peut pas être faux (nécessité : un quadrilatère a quatre côtés). Diverses interprétations des modalités donnent lieu à des applications distinctes, dont les plus importantes sont les logiques épistémiques (savoirs, croyances), déontiques (modélisant le droit) et temporelles (passé, présent, futur).
Les connaissances n'étant pas universelles, nous pouvons être conduit à des hypothèses et suppositions fausses, remises en cause à la lumière d'expériences ultérieures. Les logiques non monotones tiennent compte du fait que les exceptions sont exceptionnelles et formalisent les raisonnements où l'on adopte des hypothèses (tous les oiseaux volent) qui pourront être modifiées par des connaissances plus précises (mais pas les autruches). On raisonne avec des règles du type : si a est vrai et si b n'est pas incohérent avec ce qu'on sait, on peut déduire c (si Titi est un oiseau et si j'ignore que c'est une autruche, il vole). On autorise ainsi la prise de décision malgré une information incomplète : des suppositions plausibles permettent certaines déductions ; si, à la lumière d'informations ultérieures, ces suppositions se révèlent fausses, on remettra en question les déductions précédentes (non-monotonie).
S'agissant des grammaires , le traitement automatique des langues est un des grands domaines de l'intelligence artificielle, qui vise l'application de ses techniques aux langues humaines. Très pluridisciplinaire, il collabore avec la linguistique, la logique, la psychologie et l'anthropologie. Les travaux en traitement automatique des langues ont donné lieu à la constitution de divers ensembles de données numériques (dictionnaires de langue, de traduction, de noms propres, de conjugaison, de synonymes ; grammaires sous diverses formes ; données sémantiques), ainsi qu'à divers logiciels (analyseurs et générateurs morphologiques ou syntaxiques, gestionnaires de dialogue...). Du point de vue conceptuel, ces travaux ont produit des théories grammaticales plus compatibles avec les questions d'informatisation, des théories formelles pour la représentation du sens des mots, des phrases, des textes et des dialogues, ainsi que des techniques informatiques spécifiques pour le traitement de ces éléments sur ordinateur.
John McCarthy a inventé le langage de programmation « LISP » dès 1958 54 ( * ) , c'est un mot valise formé à partir de l'anglais list processing ou traitement de listes. De grands espoirs sont alors placés dans la compréhension du langage naturel, dans la vision artificielle, mais en fin de compte les résultats sont décevants, largement en raison des limitations de puissance du matériel disponible, des données à utiliser mais aussi des limites intrinsèques des technologies alors disponibles.
Ainsi le Perceptron , dans lequel Frank Rosenblatt plaçait tant d'espérance est rapidement critiqué. Le livre Perceptrons de Marvin Minsky et Seymour Papert, paru en 1969, démontre les limites des réseaux de neurones artificiels de l'époque 55 ( * ) .
Après cet âge d'or, qui court de 1956 au début des années 1970 , les financements sont revus à la baisse en raison de différents rapports assez critiques : les prédictions exagérément optimistes des débuts ne se réalisent pas et les techniques ne fonctionnent que dans des cas simples. À l'évidence, les difficultés fondamentales de l'intelligence artificielle furent alors largement sous-estimées en particulier la question de savoir comment donner des connaissances de sens commun à une machine. Les recherches se recentrent alors sur la programmation logique, les formalismes de représentation des connaissances et sur les processus qui les utilisent au mieux.
En dépit de cette réorientation, qui témoigne d' une certaine cyclicité des investissements en intelligence artificielle selon une boucle « espoirs-déceptions » , Marvin Minsky et ses équipes du MIT (Massachusetts Institute of Technology) développent divers systèmes (Sir, Baseball, Student..) qui relancent les recherches sur la compréhension automatique des langues.
4. Un enthousiasme renouvelé dans les années 1980 autour des systèmes experts, de leurs usages et de l'ingénierie des connaissances précède un second « hiver de l'intelligence artificielle » dans les années 1990
Au cours des années 1980, de nouveaux financements publics sont ouverts avec le projet japonais dit de « cinquième génération », le programme britannique Alvey, le programme européen Esprit et le soutien renouvelé de la DARPA aux États-Unis. Les approches sémantiques sont alors en plein essor, en lien avec les sciences cognitives, la représentation des connaissances mais surtout avec les systèmes experts et l'ingénierie des connaissances. Leurs usages dans le monde économique sont des signes de cette vitalité.
Il s'agit tout d'abord des systèmes experts , appelés aussi systèmes à base de connaissances. Un système expert est un logiciel qui vise à reproduire les raisonnements d'un expert, dans un domaine particulier. La connaissance est décrite sous la forme générale de règles :
« SI Condition (s) » « ALORS Action (s) »
Ces systèmes analysent une représentation de la situation pour voir quelles règles sont pertinentes, résolvent les éventuels conflits si plusieurs règles s'appliquent et exécutent les actions indiquées en modifiant la situation en conséquence. Ces systèmes sont efficaces dans des domaines restreints mais deviennent difficiles à gérer quand ils doivent manipuler beaucoup de règles ou dans des domaines ouverts.
Destiné au diagnostic des maladies infectieuses du sang sur la base d'un ensemble de règles déclaratives (si tels faits - alors effectuer telles actions), le premier système expert dit « MYCIN » est créé en 1974 et se diffuse dans les années 1980 . Il s'agit alors d'extraire des connaissances à partir du savoir des experts humains.
Les succès de cette approche restent relatifs car elle ne fonctionne bien que dans des domaines restreints et spécialisés. L'incapacité de l'étendre à des problèmes plus vastes renforce alors le désintérêt pour l'intelligence artificielle.
Après ce court regain d'intérêt, la recherche subit à nouveau un déclin des investissements. L'enthousiasme renouvelé dans les années 1980 autour des systèmes experts, de leurs usages et de l'ingénierie des connaissances précède donc un second « hiver de l'intelligence artificielle » dans les années 1990 .
Pour autant, des découvertes scientifiques sont réalisées dans la période. Après la renaissance de l'intérêt pour les réseaux de neurones artificiels avec de nouveaux modèles théoriques de calculs, les années 1990 voient se développer la programmation génétique ainsi que les systèmes multi - agents ou l'intelligence artificielle distribuée . La nécessité de méta-connaissances 56 ( * ) émerge également.
Les usages des systèmes experts et de l'ingénierie des connaissances persistent jusqu'à aujourd'hui ainsi que l'a expliqué Alain Berger, directeur général d'Ardans, dans son intervention lors de la journée « Entreprises françaises et intelligence artificielle » organisée par le MEDEF et l'AFIA le 23 janvier 2017 . Il a ainsi rappelé qu'il reste essentiel de faire coopérer et interopérer les connaissances et les données ; en cela, le développement d'outils précis revêt une importance capitale pour faire parvenir cette intelligence vers l'utilisateur, l'humain demeurant par son expertise la clé de validation de la connaissance. Depuis 1956, de nombreux progrès ont été accomplis, à l'instar du développement des systèmes experts, de la production et du recueil de volumes importants de données mais également de solutions coopératives. Au fil des siècles, le terme « connaissance » a évolué ; cependant, l'attachement à la compréhension d'une vérité et à sa construction a demeuré. Ce terme pourrait aujourd'hui être défini comme le fait de comprendre, de connaître les propriétés, les caractéristiques et les traits spécifiques d'une chose. Selon Alain Berger, l'ingénierie de la connaissance s'articule donc autour d'une approche de type cognitiviste, qui postule que la pensée est un processus de traitement de l'information. Le cognitivisme dans l'ingénierie de la connaissance consiste ainsi à coupler représentation et computation . La connaissance, d'un point de vue technique, vise à être structurée efficacement pour l'expert comme pour l'utilisateur ; d'un point de vue stratégique, il est essentiel de rendre explicites les savoirs tacites, de capitaliser les expériences singulières et de capitaliser les connaissances pour les préserver, les exploiter, les enrichir et les amplifier. En ce sens, l'approche cognitiviste consiste en trois clés : une structuration d'une intelligence humaine, une justification du contenu par la validation d'un expert, et l'interopérabilité avec d'autres systèmes . L'ingénierie de la connaissance fait donc figure, pour Alain Berger, de véritable tremplin de l'innovation, c'est une compétence clé pour l'organisation, en ce qu'elle permet la maîtrise de ses savoirs et la performance de ses systèmes . Il peut exister, dans le cadre de sujets exploratoires un besoin de modéliser des phénomènes, des interactions, des acteurs qui permettront de construire des scénarios et de construire de nouvelles connaissances. L'ingénierie de la connaissance a pour points forts :
- la formation des acteurs ;
- l'amélioration des compétences des acteurs d'un service ;
- la résolution de problèmes ;
- la pérennisation de l'expertise, qui est liée à un homme, à une technologie ou à un projet, la pérennisation des connaissances d'une technologie ou d'un projet.
5. Les autres domaines et technologies d'intelligence artificielle : robotique, systèmes multi-agents, machines à vecteur de support (SVM), réseaux bayésiens, apprentissage machine dont apprentissage par renforcement, programmation par contraintes, raisonnements à partir de cas, ontologies, logiques de description, algorithmes génétiques...
De très nombreux autres domaines et technologies d'intelligence artificielle peuvent être ajoutés à ceux déjà mentionnés précédemment. Certains vont être abordés au présent chapitre sans que cette liste ne soit en rien exhaustive : il ne s'agit que de quelques exemples visant à illustrer la variété et la richesse qui se cache derrière le label d'intelligence artificielle .
Le tableau académique des domaines de l'intelligence artificielle (IJCAI) retient cinq domaines : traitement du langage naturel, vision (ou traitement du signal), apprentissage automatique, systèmes multi-agents, robotique.
Mais les technologies d'intelligence artificielle sont quasi-innombrables , surtout que les chercheurs, tels des artisans, hybrident des solutions inédites au cas par cas, en fonction d'un tour de main souvent très personnel . Il s'agit d'une caractéristique propre à la recherche en intelligence artificielle, souvent peu connue à l'extérieur du cercle des spécialistes et à laquelle ont été sensibilisés vos rapporteurs.
Les domaines de l'intelligence artificielle

Source : Gouvernement (les pourcentages indiquent la répartition estimée de manière approximative des chercheurs français entre les différents domaines de l'intelligence artificielle)
L'un des premiers domaines qui peut être pris pour exemple est celui de la robotique , qui a toujours entretenu des liens très étroits avec celui de l'intelligence artificielle sans se confondre avec elle, un champ de la robotique étant hors de l'IA (les simples automates, par exemple). Pour Raja Chatila, directeur de l'Institut des systèmes intelligents et de robotique (ISIR), la problématique de l'intelligence artificielle telle que posée par Alan Turing 57 ( * ) était de savoir si les ordinateurs pouvaient être capables de « pensée » ( Can Machines Think? ) et il l'a traduite par la question de l'imitation de l'homme. Or les fondateurs de « l'intelligence artificielle » dans les années 1950 ont orienté la problématique vers celle de l'« intelligence », ou de « mécanismes de haut niveau ».
Cette manière de poser la question néglige un constat pourtant simple : au fil des ères (de la reptation à la bipédie, de la cueillette à l'agriculture, de la chasse à l'élevage par exemple), le cerveau humain a évolué vers ce qu'il est grâce au développement des capacités de perception, d'interprétation, d'apprentissage et de communication en vue d'une action plus efficace, de plus en plus déterminée par la volonté et des choix rationnels. Or la problématique de la robotique pose l'ensemble de ces questions. Le robot-machine est soumis à la complexité du monde réel dans lequel il évolue et dont il doit respecter la dynamique. La notion d'intelligence doit alors être posée de manière à rendre compte globalement des processus sensori-moteurs, perceptuels et décisionnels permettant l'interaction en temps réel avec le monde en tenant compte des contraintes d'incomplétude et d'incertitude de perception ou d'action. C'est le sens de la définition de la robotique donnée par Mike Brady (Oxford) dans les années 1980 : « La robotique est le lien intelligent entre la perception et l'action. » Dans ce sens on peut dire que le robot est le paradigme de l'intelligence artificielle « encorporée », c'est-à-dire une intelligence matérialisée dans un environnement qu'elle découvre et dans lequel elle agit.
Il est nécessaire, selon Raja Chatila, d'adopter une vision d'ensemble du robot, en tant que système intégrant ses différentes capacités (perception/interprétation, mouvement/action, raisonnement/planification, apprentissage, interaction) et permettant à la fois la réactivité et la prise de décision sur le long terme. Ces fonctions doivent être intégrées de manière cohérente dans une architecture de contrôle globale (architecture cognitive) ; leur étude de manière séparée risque d'aboutir à des solutions inappropriées.
De nombreuses avancées ont été réalisées dans chacune des fonctions fondamentales du robot : perception, action, apprentissage . Dans les années 1985-2000, la problématique de la localisation et de la cartographie simultanées a connu un développement formidable qui a permis de bien en cerner les fondements et de produire des systèmes efficaces, le point faible important restant le manque d'interprétations plus sémantiques de l'environnement et des objets qui le composent.
Un autre domaine est celui des systèmes multi-agents ou l'intelligence artificielle distribuée , inspirée des comportements sociaux et notamment de certaines familles d'insectes, permettant la mise en oeuvre de systèmes qui s'auto-organisent. Ces comportements sociaux peuvent être programmés de manière plus ou moins complexe et intégrer des croyances, des désirs et des intentions.
Vos rapporteurs ont expérimenté ces systèmes lors d'une rencontre avec les chercheurs du laboratoire de robotique et d'intelligence artificielle de l'Université Libre de Bruxelles dirigé par le professeur Hugues Bersini. Une colonie de petits robots peu intelligents travaillent ensemble, développent une coopération puis des stratégies plus complexes que ce que leur permet leur intelligence individuelle et démontrent ainsi la pertinence de l'intelligence collective. Les travaux de Michael Wooldridge sur les systèmes multi-agents, chercheur également rencontré par vos rapporteurs, illustrent les résultats de ces méthodes d'intelligence artificielle distribuée. Les systèmes multi-agents et l'intelligence artificielle distribuée renvoient donc à des formes collectives de décision . Le développement de systèmes de plus en plus complexes implique l'utilisation de connaissances expertes, hétérogènes, plus ou moins indépendantes les unes des autres. Différents experts n'aboutissant pas toujours au même résultat, il faut confronter leurs décisions pour prendre une décision. Les architectures classiques (des modules qui s'enchaînent dans un ordre prédéfini) ont alors été remises en cause au profit d'architectures multi-agents. Alors qu'un agent est un logiciel autonome percevant son environnement et agissant dessus, un système multi-agent est constitué d'un ensemble de tels agents, partageant des ressources communes et communiquant entre eux .
On trouve principalement des agents peu complexes, n'utilisant ni buts ni plans (et qui sont généralement en grand nombre) ou des agents disposant de buts, de plans, de croyances et de connaissances (ces agents plus élaborés sont souvent peu nombreux). Le point crucial de tels systèmes concerne la coordination entre les agents . Pour ce faire, différents modes de communication entre agents sont possibles :
- soit chaque agent analyse les données contenues dans une zone commune et, s'il en trouve qu'il peut utiliser, il les traite et écrit de nouvelles données à utiliser par d'autres agents ;
- soit l'agent concerné quand il rencontre un problème envoie un message à d'autres agents afin de trouver qui peut l'aider à le résoudre. Le système adapte ainsi de manière dynamique son comportement à la situation à traiter.
La coordination est un aspect important, mais des systèmes multi-agents peuvent mettre l'accent sur d'autres caractéristiques, à l'instar du modèle Voyelles développé par Yves Demazeau en 1995 et qui insiste sur les relations entre les agents, l'environnement, les interactions et l'organisation.
L' évolution artificielle et la programmation génétique 58 ( * ) donnent lieu à l'élaboration d'algorithmes génétiques ou algorithmes évolutifs, qui imitent la façon dont la vie biologique a évolué sur terre. En effet, il est loisible d'interpréter le monde d'aujourd'hui comme une succession de stratégies gagnantes. Les espèces qui ont survécu à la sélection naturelle sont autant d'exemples de réussite. La nature a, par tâtonnement, créé un grand nombre de combinaisons de codes génétiques qu'elle a ensuite sélectionnés dans la mesure où ils fonctionnent, survivent et parviennent à dominer leur environnement. Les algorithmes génétiques appliquent les mécanismes fondamentaux de l'évolution et de la sélection naturelle pour cartographier des espaces de paramètres et surtout répondre à des problèmes d'optimisation . On code les caractéristiques des objets manipulés et on définit une fonction qui évalue la valeur attribuée à chaque objet. On fait évoluer une population initiale en créant de nouveaux objets à partir des anciens et en permettant diverses mutations. La sélection permet d'éliminer les objets les moins efficaces . Ce type de processus donne de bons résultats dans divers domaines, la difficulté résidant dans le choix du codage (c'est-à-dire les paramètres pertinents des objets considérés) et les types de mutations autorisées.
Les réseaux bayésiens , qui se situent à l'intersection de l'informatique et des statistiques 59 ( * ) , donnent de bons résultats parmi les technologies d'intelligence artificielle. Un réseau bayésien est un outil mathématique de modélisation graphique probabiliste et d'analyse de données. La modélisation est graphique en ce qu'elle représente les variables aléatoires sous la forme d'un graphe orienté 60 ( * ) . Judea Pearl, prix Turing 61 ( * ) 2011 pour « ses contributions fondamentales à l'intelligence artificielle par le développement de l'analyse probabiliste et du raisonnement causal », est l'un des inventeurs de ces modèles. Ils sont particulièrement adaptés à la prise en compte de l'incertitude et peuvent être décrits manuellement par des experts ou produits automatiquement par apprentissage. Un réseau bayésien permet de représenter la connaissance acquise (modèle de représentation des connaissances) ou de découvrir la connaissance dans un contexte par l'analyse de données (c'est une machine à calculer les probabilités conditionnelles), afin de mener des opérations de prise de décisions, de diagnostic, de simulation et de contrôle d'un système. L'intérêt particulier des réseaux bayésiens est de tenir compte simultanément de connaissances a priori d'experts (dans le graphe) et de l'expérience contenue dans les données, ce qui est très pertinent pour l'aide à la décision.
Les réseaux bayésiens sont donc souvent utilisés pour des solutions décisionnelles qui correspondent souvent aux défis lancés aux technologies d'intelligence artificielle.
Michael Jordan, professeur à l'Université de Berkeley, que vos rapporteurs ont rencontré, identifie quatre pistes sur lesquelles il fait particulièrement travailler ses équipes, qui s'inscrivent dans le prolongement des modèles graphiques probabilistes et en particulier des réseaux bayésiens, dont il est une des figures avec Judea Pearl et Daphne Koller. Il décrit ainsi quatre axes de recherche pertinents : les variables latentes, les modèles topiques, les modèles de causalité et les séries temporelles .
Deux autres outils d'intelligence artificielle sont rappelés ici. La programmation par contraintes , qui se rapproche de certains raisonnements humains, et les raisonnements à partir de cas , qui se fondent sur la notion d'analogie mais tend à devenir plus marginal.
Dans certains problèmes, on connaît les valeurs possibles que peuvent prendre certaines des variables - on parle alors de contraintes. Résoudre le problème consiste alors à affecter à chaque variable une valeur satisfaisant ces contraintes. L'évolution de Prolog système, évoqué plus haut, a été fondée sur cet aspect. Cette technique de programmation par contraintes , d'origine française, permet des raisonnements locaux, en simplifiant le problème global en sous-problèmes partiels, puis une propagation des contraintes sur l'ensemble du problème . Elle est largement utilisée en biologie moléculaire, en conception de produits industriels, en planification de production, en gestion du trafic dans les villes et les aéroports. Ses limites sont patentes dans les problèmes dynamiques (où les contraintes varient dans le temps) ou dans les problèmes « sur-contraints » (dans les cas où il n'existe pas de solution qui vérifie toutes les contraintes). Le fait de savoir quelles contraintes négliger ou privilégier reste un problème ouvert.
Le raisonnement à partir de cas se fonde sur des analogies entre des expériences passées et un problème actuel . On mémorise un certain nombre de situations spécifiques dans un domaine donné (les « cas ») et, devant un nouveau problème, on essaye de trouver le ou les cas les plus proches, puis on transpose les solutions déjà rencontrées au nouveau problème. C'est typiquement le raisonnement utilisé par la justice pour adapter la jurisprudence à une nouvelle situation . Deux étapes sont nécessaires pour ce type de raisonnement : l'indexation, qui sert à trouver les cas pertinents pour le problème actuel, et l'adaptation, pour modifier un ou plusieurs cas et les rendre applicables au problème actuel. Les métriques permettant l'indexation calculent une mesure de similarité entre cas. La difficulté essentielle de ce type de raisonnement étant de trouver le chemin qui va de la solution du cas connu au problème en cours, sachant que les métriques les plus élaborées tentent d'en tenir compte.
Pour comprendre l' apprentissage automatique ou machine learning , il est loisible d'introduire, comme le préconise Jean-Claude Heudin, les concepts de « prédicteur » et de « classifieur ». Ce dernier est une machine capable d'approximer un processus 62 ( * ) dont on ne connaît pas a priori le modèle. Le calcul de la sortie en fonction des données présentées en entrée est appelé une régression. Un classifieur est une machine qui va plus loin qu'un simple prédicteur, c'est aussi une fonction linéaire, mais elle permet de différencier des éléments appartenant à des catégories différentes lorsque ces catégories sont clairement séparables.
Le mot algorithme est issu, comme il a été vu, de la latinisation du nom du mathématicien Al-Khawarizmi et correspond à une suite finie et non ambiguë d'opérations ou d'instructions permettant de résoudre un problème ou d'obtenir un résultat . La difficulté liée aux algorithmes classiques réside dans le fait que l'ensemble de tous les comportements possibles, compte tenu de toutes les entrées possibles, devient rapidement trop complexe à décrire. Cette explosion combinatoire justifie de confier à des programmes le soin d'ajuster un modèle adaptatif permettant de simplifier cette complexité et de l'utiliser de manière opérationnelle en prenant en compte l'évolution de la base des informations pour lesquelles les comportements en réponse ont été validés. C'est ce que l'on appelle l' apprentissage automatique ou machine learning , qui permet donc au programme d'apprendre et d'améliorer le système d'analyse et/ou de réponse. En ce sens, on peut dire que ces types particuliers d'algorithmes apprennent .
Un apprentissage est dit « supervisé » lorsque l'algorithme définit des règles à partir d'exemples qui sont autant de cas validés . Ces exemples sont appelés bases de données d'apprentissage. Jean-Claude Heudin parle ainsi de méthode itérative, autrement dit un algorithme, visant à ajuster les paramètres d'un classifieur linéaire en fonction de l'erreur qu'il commet entre la sortie souhaitée et la sortie obtenue grâce aux exemples que sont les données d'apprentissage. La correction à apporter à chaque étape au paramètre du classifieur peut être calculée simplement en faisant le rapport de l'erreur sur la valeur d'entrée. Une meilleure performance est obtenue en modérant les ajusements par un taux d'apprentissage. Le classifieur peut aussi être non linéaire en vue de séparer des données qui ne sont pas elles-mêmes régies par un processus linéaire 63 ( * ) . Les réseaux de neurones artificiels, analysés plus loin, représentent une multiplication de classifieurs non linéaires dotés de paramètres d'ajustement (il s'agit de coefficients qui sont appelés de manière métaphorique les « poids synaptiques »).
À l'inverse de l'apprentissage supervisé, lors d'un apprentissage « non supervisé » , le modèle est laissé libre d'évoluer vers n'importe quel état final lorsqu'un motif ou un élément lui est présenté.
Entre ces deux formes d'apprentissage, l'apprentissage automatique ou machine learning peut-être semi-supervisé ou partiellement supervisé .
L'apprentissage automatique peut lui-même reposer sur plusieurs méthodes : l'apprentissage par renforcement , l'apprentissage par transfert, ou, encore, l'apprentissage profond , qui sera vu plus loin.
L'apprentissage par renforcement conduit l'algorithme à apprendre, à partir d'expériences ou d'observations, un comportement optimal ou stratégie, selon une logique itérative de recherche de récompenses , un peu comme dans le cas du dressage d'un animal. L'action de l'algorithme sur un environnement donné produit une valeur de retour qui guide son apprentissage dans la mesure où l'algorithme cherche dans ce cadre d'apprentissage par renforcement à optimiser sa fonction de récompense quantitative au cours des expériences. Par exemple, l'algorithme de « Q-learning », qui optimise les actions accessibles sans même avoir de connaissance initiale de l'environnement par une comparaison de récompenses probables, est un cas d'apprentissage par renforcement.
L'apprentissage par transfert peut être vu comme la capacité d'un système à reconnaître à partir de tâches antérieures apprises des connaissances et des compétences, puis à appliquer ces dernières sur de nouvelles tâches partageant des similitudes.
L'apprentissage supervisé permet, de plus, des méthodes prédictives utiles en reconnaissance de formes, selon plusieurs approches : les arbres de décision , les réseaux bayésiens ou, encore, les machines à vecteurs de support .
Avec les arbres de décision 64 ( * ) , les algorithmes d'apprentissage supervisés peuvent calculer automatiquement à partir de bases de données, en sélectionnant automatiquement les variables discriminantes à partir de données peu structurées et potentiellement volumineuses. Ils peuvent ainsi permettre d'extraire des règles logiques de cause à effet (des déterminismes) ou, au moins, des corrélations , qui n'apparaissaient pas immédiatement dans les données brutes .
Avec les réseaux bayésiens , qui ont été mentionnés plus hauts, l'apprentissage automatique peut être utilisé de deux façons : pour estimer la structure d'un réseau, ou pour estimer les tables de probabilités d'un réseau, dans les deux cas à partir de données. L'intérêt particulier des réseaux bayésiens est de tenir compte simultanément de connaissances a priori d'experts et de l'expérience contenue dans les données .
Les machines à vecteurs de support (en anglais support vector machines ou SVM), parfois appelées séparateurs à vaste marge sont des techniques d'apprentissage supervisé reposant sur les notions de marge maximale et de fonction noyau, destinées à résoudre des problèmes de discrimination et de régression . Il s'agit de classifieurs linéaires 65 ( * ) dont les excellentes capacités de généralisation leur ont permis d'être l'une des technologies dominantes en intelligence artificielle dans les années 1990 et 2000.
La méthode Monte-Carlo 66 ( * ) et la méthode du recuit simulé 67 ( * ) , techniques plus anciennes, sont d'autres méthodes dont le but est de trouver une solution optimale pour un problème donné et qui peuvent se combiner avec les technologies d'apprentissage automatique.
Les réseaux de neurones artificiels prennent en compte l'apprentissage de manière dite « implicite » ou, en tout état de cause, plus implicite que l'ensemble des méthodes qui viennent d'être présentées.
Un réseau de neurones artificiels est constitué d'un ensemble d'éléments interconnectés, chacun ayant des entrées et des sorties numériques . Le comportement d'un neurone artificiel dépend de la somme pondérée de ses valeurs d'entrée et d'une fonction de transfert. Si cette somme dépasse un certain seuil, la sortie prend une valeur positive, sinon elle reste nulle . Ainsi que l'explique Jean-Claude Heudin, ces réseaux sont des « automates à seuil qui réalisent la somme pondérée de leurs entrées. Les coefficients synaptiques et le seuil d'activation permettent d'ajuster leur comportement ». Le neurone formel peut être amélioré en utilisant des valeurs numériques au lieu d'un comportement binaire. Pour ce faire, la fonction à seuil est remplacée par une fonction sigmoïde 68 ( * ) , les calculs restent néanmoins élémentaires. Un réseau de neurones artificiels comporte une couche d'entrée (les données), une couche de sortie (les résultats), et peut comporter une ou plusieurs couches intermédiaires , avec ou sans boucles.
Le principe de fonctionnement consiste, dans une première phase, à présenter en entrée les valeurs correspondant à de nombreux exemples, et en sortie les valeurs respectives des résultats souhaités.
Cet apprentissage permet d'ajuster les poids synaptiques , qui sont donc des coefficients capables de s'auto-ajuster, afin que les correspondances entre les entrées et les sorties soient les meilleures possible .
Après un nombre statistiquement pertinent d'exemples, l'apprentissage (implicite) est terminé et le réseau peut être utilisé, dans une seconde phase, pour la reconnaissance. Comme il produit toujours une sortie, même pour des entrées non rencontrées auparavant, il a le plus souvent une bonne capacité de généralisation, qui dépend du corpus d'apprentissage .
Il s'agit donc de combiner de nombreuses fonctions simples pour former des fonctions complexes et d' apprendre les liens entre ces fonctions simples à partir d'exemples étiquetés .
L'analogie avec le fonctionnement du cerveau humain repose sur le fait que les fonctions simples rappellent le rôle joué par les neurones, tandis que les connexions rappellent les synapses.
Il ne s'agit en aucun cas de réseaux de neurones de synthèse , ce n'est qu'une image. Cette métaphore biologique est sans doute malheureuse selon vos rapporteurs, car elle entretient une forme de confusion , en lien avec celle produite également par la notion d' intelligence artificielle .
Schéma d'un réseau de neurones
artificiels
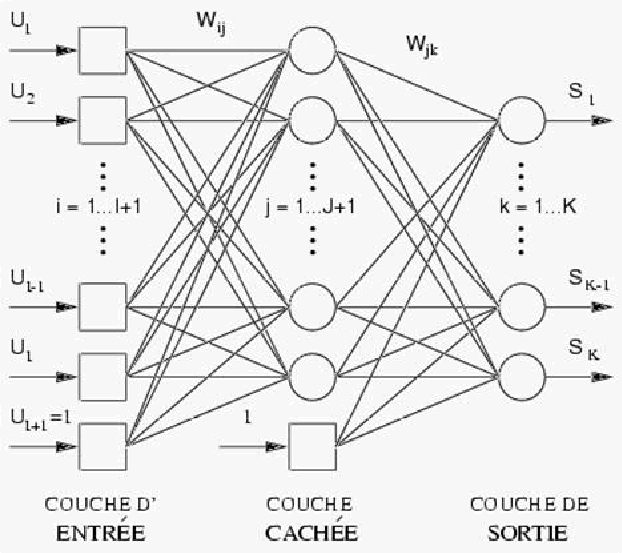
Source : Académie des technologies
Les applications nécessitent des structures aux couches de plus en plus conséquentes, malheureusement comme l'explique Jean-Claude Heudin, plus le nombre de couches augmente et plus les problèmes de surajustement ( overfitting ) et de disparition des gradients ( vanishing gradient ) deviennent gênants, sans même parler des temps de calcul qui explosent.
D'autres technologies peuvent encore être citées comme la recherche dans les espaces d'états, la planification (très efficace au jeu d'échecs), les ontologies, les logiques de description... Les domaines de l'intelligence artificielle, comme le traitement du langage naturel ou la vision artificielle utilisent plusieurs des technologies disponibles, qui, comme il sera vu plus loin, peuvent de plus se combiner entre elles .
Dans la période récente, un système d'intelligence artificielle nommé Libratus , créé par le professeur Tuomas Sandholm et son doctorant Noam Brown, tous deux chercheurs de l'Université Carnegie Mellon de Pittsburgh, a affronté et battu en janvier 2017 quatre joueurs de poker professionnels dans un casino de Pennsylvanie, au cours d'une partie de poker 69 ( * ) de 120 000 mains successives sur 20 jours, intitulée « Cerveau contre Intelligence Artificielle : on monte la mise » (« Brains Vs. Artificial Intelligence : Upping the Ante »). Sa victoire sans appel, avec un gain de 1,8 million de dollars (contre des pertes pour tous les autres joueurs), marque à son tour l'histoire des progrès des systèmes d'intelligence artificielle , surtout que le poker requiert une forme de raisonnement particulièrement difficile à imiter pour une machine . Libratus a utilisé les capacités de calcul du superordinateur de l'Université Carnegie Mellon et combiné des algorithmes de Public Chance Sampling (PCS, à ce stade non traduit en français et qui signifie « Échantillonnage de hasard public »), variante de la « réduction des regrets contrefactuels » 70 ( * ) (Counterfactual Regret Minimization ou CFR), avec la méthode d'Oskari Tammelin introduite en 2014, permettant l'optimisation des résultats dans un contexte d'informations imparfaites 71 ( * ) . Un article collectif paru dans la revue Science en 2015 présentait déjà les évolutions théoriques nécessaires à cette victoire 72 ( * ) .
En effet, un joueur de poker ne connaît pas les ressources (cartes) et les stratégies (sincérité ou pas) de son adversaire et doit donc agir sans informations certaines et sans écarter la possibilité d'un bluff. La réflexion de la machine au poker doit donc prendre en compte des données incomplètes ou dissimulées ce qui distingue le poker d'autres jeux comme le Go ou les échecs , dans lesquels l'intelligence artificielle avait déjà démontré sa supériorité sur l'homme. Le poker fait intervenir les notions de hasard, de piège et de bluff, alors que les jeux où dominaient l'intelligence artificielle jusqu'en janvier 2017 étaient fondés sur des stratégies relevant de l'analyse combinatoire : les deux adversaires s'y affrontaient en continu en visualisant l'ensemble du jeu et des pions.
Cette victoire de Libratus en 2017 n'a reposé que sur des duels, la machine jouant contre un seul joueur à la fois. La prochaine étape pour les développeurs sera d'assurer la victoire d'une intelligence artificielle dans des parties à plusieurs. Tuomas Sandholm et Noam Brown travaillent à ce nouveau projet.
De manière caricaturale, on pourrait résumer les technologies d'intelligence artificielle à un champ de recherche où s'opposent deux grands types d'approches : les approches symboliques et les approches connexionnistes . Comme il a été vu à travers la description des nombreuses technologies développées, la réalité est souvent plus complexe que cette opposition, puisqu'il existe une multitude de technologies, qui, de plus, peuvent se conjuguer. Parmi les approches connexionnistes, voire parmi toutes les familles d'approches en intelligence artificielle, l'apprentissage profond ou « deep learning » est devenu dominant au cours des dernières décennies, en particulier au cours des quatre dernières années.
Pour la DARPA, dont vos rapporteurs ont rencontré les responsables, ces deux grands types d'approches peuvent se voir donner le nom de « savoirs artisanaux » (ou faits à la main, en anglais handcrafted knowledges ) pour la première et d'apprentissages statistiques ( statistical learning ) pour la deuxième, sachant qu'une troisième génération d'approche de l'intelligence artificielle devrait bientôt advenir : celle de l'adaptation contextuelle ( contextual adaptation ).
* 41 Jean-Claude Heudin, Robots et avatars : Le rêve de Pygmalion et Les créatures artificielles : des automates aux mondes virtuels , Michel de Pracontal, L'Homme artificiel, Golems, robots, clones, cyborgs.
* 42 Bruce G. Buchanan « A (Very) Brief History of Artificial Intelligence », AI Magazine, 2005.
* 43 En 1834, pendant le développement d'une machine à calculer, Charles Babbage imagine le premier ordinateur sous la forme d'une « machine à différences » en utilisant la lecture séquentielle des cartes du métier à tisser Jacquard afin de donner des instructions et des données à sa machine. En cela, il fut le premier à énoncer le principe d'un ordinateur.
* 44 Donald Knuth, pionnier de l'algorithmique moderne ( The Art of Computer Programming ), a identifié les cinq propriétés suivantes comme étant les prérequis d'un algorithme : la finitude (« Un algorithme doit toujours se terminer après un nombre fini d'étapes »), une définition précise (« Chaque étape d'un algorithme doit être définie précisément, les actions à transposer doivent être spécifiées rigoureusement et sans ambiguïté pour chaque cas »), l'existence d'entrées (« des quantités lui sont données avant qu'un algorithme ne commence. Ces entrées sont prises dans un ensemble d'objets spécifié ») et de sorties (« des quantités ayant une relation spécifiée avec les entrées ») et un rendement (« toutes les opérations que l'algorithme doit accomplir doivent être suffisamment basiques pour pouvoir être en principe réalisées dans une durée finie par un homme utilisant un papier et un crayon »).
* 45 « Computing Machinery and Intelligence » , Mind, octobre 1950.
* 46 Le test de Turing consiste à mettre en confrontation verbale un humain avec un ordinateur imitant la conversation humaine et un autre humain. Dans le cas où l'homme qui engage les conversations n'est pas capable de dire lequel de ses interlocuteurs est un ordinateur, on peut considérer que le logiciel de l'ordinateur a passé avec succès le test.
* 47 « A Logical Calculus of Ideas Immanent in Nervous Activity » , 1943, Bulletin of Mathematical Biophysics 5.
* 48 « The Perceptron : A Probabilistic Model for Information Storage and Organization in the Brain ».
* 49 « What the frog's eye tells the frog's brain » ou « ce que l'oeil d'une grenouille dit à son cerveau » , coécrit avec Jerome Lettvin et Humberto Maturana, 1959, Proceedings of the Institute of radio engineers.
* 50 L'anthropomorphisme est l'attribution de caractéristiques du comportement humain ou de la morphologie humaine à d'autres entités comme des dieux, des animaux, des objets ou d'autres phénomènes. L'essentialisme est l'attribution à un être ou à un objet d'une existence propre « par essence », c'est-à-dire inhérente au sujet en question.
* 51 Si l'on met de côté la « machine de Turing » qui relève de l'informatique théorique, le « système A-0 » (ou « A-0 System ») est le premier compilateur (programme qui transforme un code source écrit dans un langage de programmation ou langage source en un autre langage informatique, appelé langage cible) développé en 1952 ; il est suivi notamment par le Fortran (mot valise issu de l'anglais « formula translator ») inventé dès 1954, Lisp et Algol en 1958, COBOL (acronyme de « Common Business Oriented Language ») en 1959, BASIC (acronyme de « Beginner's All-purpose Symbolic Instruction Code ») en 1964, Logo en 1967, Pascal en 1971, ou, encore, Prolog (mot valise pour Programmation logique), inventé par des chercheurs français en 1972.
* 52 Il faudra attendre 1997 pour que le champion d'échecs Garry Kasparov s'incline devant le système Deep Blue d'IBM.
* 53 Des symboles permettent alors de représenter des faits et des règles permettent d'en déduire de nouveaux.
* 54 « Fonctions Récursives d'expressions symboliques et leur évaluation par une Machine » ou « Recursive Functions of Symbolic Expressions and Their Computation by Machine » , Communications of the ACM, Avril 1960.
* 55 La critique principale concerne l'incapacité du perceptron à résoudre les problèmes non linéairement séparables, tels que le problème du « X OR » (« OU exclusif »). Il s'en suivra alors, en réaction à la déception, une période noire d'une vingtaine d'années pour les réseaux de neurones artificiels.
* 56 Il s'agit de connaissances à propos des connaissances elles-mêmes.
* 57 A. M. Turing (1950) Computing Machinery and Intelligence . Mind 49: 433-460.
* 58 Il s'agit d'une technique de programmation inspirée des mécanismes d'évolution et de sélection génétique des organismes vivants.
* 59 Les modèles de régression linéaire sont aussi utilisés comme méthode d'apprentissage supervisé pour prédire une variable quantitative. Ils peuvent aider à prédire un phénomène ou chercher à l'expliquer. L'inventeur de la notion en 1886, Francis Galton, mettait en évidence, dans un article fondateur, un phénomène de « régression vers la moyenne » en analysant la taille des fils en fonction de la taille de leurs pères. Avant cela, Carl Friedrich Gauss avait démontré, dès 1821, un théorème relatif à l'estimateur linéaire selon la méthode des moindres carrés, connu aujourd'hui sous le nom de « théorème de Gauss-Markov », car redécouvert et complété en 1900 par Andrei Markov. Ce dernier a ainsi mis en évidence les processus aléatoires dans le calcul des probabilités. Ces aléas, ou « chaînes de Markov » sont les fondements théoriques du calcul stochastique.
* 60 Pour un domaine donné, on décrit les relations causales entre variables d'intérêt par un graphe. Dans ce graphe, les relations de cause à effet entre les variables ne sont pas déterministes, mais probabilisées. Ainsi, l'observation d'une cause ou de plusieurs causes n'entraîne pas systématiquement l'effet ou les effets qui en dépendent, mais modifie seulement la probabilité de les observer.
* 61 Ce prix est la plus haute distinction en informatique.
* 62 Le comportement du processus est approximé grâce à un modèle qui comprend un ensemble de paramètres ajustables. Une bonne approche pour ajuster les paramètres est de les modifier progressivement de façon à minimiser l'erreur que le prédicteur produit lorsqu'on lui présente des données dont on connaît la sortie correspondante.
* 63 L'exemple le plus connu est celui des opérateurs booléens (du nom du mathématicien George Boole) « Ou - Exclusif » (en anglais « X-OR »). Un classifieur linéaire peut traiter des opérations « Et » ou « Ou » mais bute sur le « Ou - Exclusif ». Les opérateurs booléens recourent à la solution « Non - Et » (en anglais « Nand »).
* 64 Un arbre de décision est un outil d'aide à la décision représentant un ensemble de choix sous la forme graphique d'un arbre.
* 65 Algorithmes de classement statistique, les classifieurs permettent de classer dans des groupes des échantillons qui ont des propriétés similaires, mesurées par des observations. Un classifieur linéaire en est un type particulier, qui calcule la décision par combinaison linéaire des échantillons.
* 66 Il s'agit de méthodes algorithmiques visant à calculer une valeur numérique approchée en utilisant des techniques probabilistes ou aléatoires. Nicholas Metropolis a utilisé le nom de méthode Monte-Carlo en 1947 en faisant allusion aux jeux de hasard pratiqués au casino de Monte-Carlo.
* 67 Adapté par des chercheurs d'IBM en 1983, le recuit simulé est une méthode empirique ou méta-heuristique cherchant à optimiser les chances de découvertes des extrêmes d'une fonction. Elle est inspirée d'un processus traditionnel utilisé en métallurgie, qui consiste à alterner des cycles de refroidissement lent et de réchauffage dans le but de minimiser l'énergie du matériau. Elle a été théorisée en 1985 par S. Kirkpatrick, C.D. Gelatt et M.P. Vecchi, et indépendamment par V. Èerny.
* 68 La fonction sigmoïde a globalement la même forme que la fonction à seuil, mais les changements de valeur entre 0 et 1 sont plus progressifs : la courbe est plus douce et moins abrupte. L'équation de la fonction sigmoïde est la suivante : y = 1 / (1 + e -x ).
* 69 Il s'agit de parties de poker « Texas Hold'em », en face à face ou heads-up et sans limite de mise ou no limit .
* 70 Cf. https://www.quora.com/What-is-an-intuitive-explanation-of-counterfactual-regret-minimization
* 71 Cf. https://arxiv.org/abs/1407.5042