







B. L'ACCÉLÉRATION RÉCENTE DE L'USAGE DES TECHNOLOGIES D'INTELLIGENCE ARTIFICIELLE GRÂCE AUX PROGRÈS EN APPRENTISSAGE AUTOMATIQUE (« MACHINE LEARNING »)
1. Les découvertes en apprentissage profond (« deep learning ») remontent surtout aux années 1980, par un recours aux « réseaux de neurones artificiels » imaginés dès les années 1940
Les technologies d'apprentissage profond ou « deep learning » rencontrent un succès particulièrement remarquable dans les années 2010 , pourtant elles sont anciennes. Leur essor doit beaucoup à l'émergence récente de la disponibilité de données massives (« big data ») et à l'accélération de la vitesse de calcul des processeurs, mais leur histoire remonte aux années 1940, ce que vos rapporteurs ont évoqué précédemment mais jugent nécessaire de rappeler de façon plus détaillée ici : comme il a été vu les « réseaux de neurones artificiels » sont imaginés dès les années 1940 73 ( * ) et aboutissent au Perceptron à la fin des années 1950. En 1957, au laboratoire d'aéronautique de l'Université Cornell, Frank Rosenblatt invente ce dernier à partir des travaux de McCulloch et Pitts, ce qui constitue la première modélisation d'un réseau de neurones artificiels , dans sa forme la plus simple, à savoir un classifieur linéaire 74 ( * ) . Marvin Minsky ayant pointé, comme il a été, vu les défauts de ce système, des perceptrons multicouches ont ensuite été proposés en 1986, parallèlement, par David Rumelhart et Yann LeCun.
Les réseaux de neurones artificiels peuvent être à apprentissage supervisé ou non (ils sont le plus souvent supervisés, comme dans le cas du Perceptron), avec ou sans rétropropagation ( back propagation ) .
Outre les réseaux multicouches, d'importantes découvertes en apprentissage profond (« deep learning ») remontent aux années 1980, telles que la rétropropagation du gradient . Les pionniers de ces découvertes sont Paul Werbos, David Parker, et le Français Yann LeCun rencontré plusieurs fois par vos rapporteurs. David Rumelhart, Geoffrey Hinton et Ronald Williams théorisent cette découverte en 1986 dans un fameux article intitulé Learning representations by back-propagating errors 75 ( * ) . L'idée générale de la rétropropagation consiste à rétropropager l'erreur commise par un neurone à ses synapses et aux neurones qui y sont reliés.
Le principe de rétropropagation du gradient fonde les méthodes d'optimisation utilisées dans les réseaux de neurones multicouches , comme les perceptrons multicouches. Il s'agit en effet de faire converger l'algorithme de manière itérative vers une configuration optimisée des poids synaptiques . L'algorithme étant itératif, la correction s'applique autant de fois que nécessaire pour obtenir une bonne prédiction. Une vigilance est requise face aux problèmes de surapprentissage liés à un mauvais dimensionnement du réseau ou un apprentissage trop poussé.
La correction des erreurs peut aussi se faire selon d'autres méthodes, en particulier le calcul de la dérivée seconde .
L'apprentissage profond ou deep learning regroupe donc des méthodes plus récentes d'apprentissage automatique , ou machine learning dont elles sont une sous-catégorie .
Ces méthodes, parfois qualifiées de révolution dans le domaine de l'intelligence artificielle , ont pour spécificité d'utiliser des modèles de données issus d'architectures articulées en différentes couches d'unité de traitement non linéaire, qui sont autant de niveaux d'abstraction des données . La façon de rétropropager l'erreur au sein de plusieurs couches cachées permet de généraliser plus efficacement, ce qui permet des représentations de plus haut niveau et une capacité à traiter des données plus complexes.
Selon Yann LeCun « Les cerveaux humain et animal sont "profonds", dans le sens où chaque action est le résultat d'une longue chaîne de communications synaptiques (de nombreuses couches de traitement). Nous recherchons des algorithmes d'apprentissage correspondants à ces "architectures profondes". Nous pensons que comprendre l'apprentissage profond ne nous servira pas uniquement à construire des machines plus intelligentes, mais nous aidera également à mieux comprendre l'intelligence humaine et ses mécanismes d'apprentissages ».
L'apprentissage profond a récemment fait une incursion considérable en robotique , contestant la place dominante de l'apprentissage bayésien, à la fois pour la perception et pour la synthèse d'actions.
Mais, comme le remarque Raja Chatila, la perception en robotique nécessite une interaction du robot avec son environnement et non une simple observation de celui-ci . L'apprentissage par renforcement est particulièrement pertinent ici (le cas échéant en complément de l'apprentissage profond) car il est un apprentissage souvent non supervisé qui permet au robot de découvrir à la fois les effets de ses actions, caractérisés par une « récompense » obtenue comme conséquence de l'action, et l'incertitude de ses actions qui n'ont pas toujours les mêmes effets. Le lien entre perception et apprentissage - en particulier avec l'apprentissage par renforcement - est essentiel pour extraire la notion d' affordance qui rend compte des propriétés des objets en ce qu'elles représentent pour l'agent, et qui associe les représentations perceptuelles aux capacités d'action. C'est cela qui sert de base au robot pour exprimer le sens du monde qui l'entoure.
L' affordance , courante en ergonomie et en design , évoque la potentialité ou la capacité d'un système à suggérer sa propre utilisation , sans qu'il soit nécessaire de lui fournir un mode d'emploi. Issue de la psychologie 76 ( * ) , la notion renvoie d'abord à toutes les possibilités d'actions sur un objet puis a évolué vers les seules possibilités dont l'acteur est conscient. Cette utilisation intuitive est importante en robotique.
2. L'apprentissage profond connaît un essor inédit dans les années 2010 avec l'émergence de la disponibilité de données massives (« big data ») et l'accélération de la vitesse de calcul des processeurs
En deep learning , toute chose étant égale par ailleurs, les algorithmes donnent des résultats d'autant plus performants que les données sont massives, variées, rapides et pertinentes : ce sont les quatre V du big data , à savoir un volume croissant de données, issues d'une large variété de sources, qui circulent à une vitesse élevée et dont la véracité assure la cohérence.
Les « Quatre V » du big data
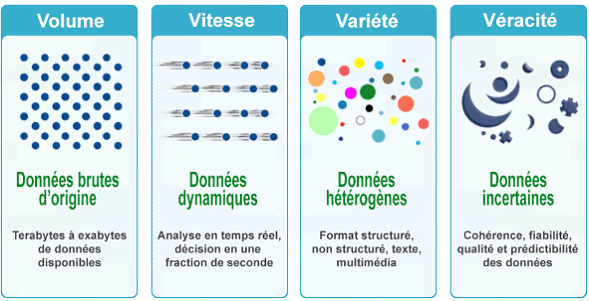
Source : Thierry Lombry, http://www.astrosurf.com/luxorion/big-data-mining.htm
S'agissant du volume de données, il a eu pour condition la capacité croissante en matière de stockage de ces dernières . Les supports de stockage des données ont rapidement évolués ces dernières décennies et sont de plus en plus divers.
Supports de stockage des données

Source : Thomas Hauet, maître de conférences à l'Université de Lorraine
Les disques durs des ordinateurs ont vu leur capacité de stockage suivre une croissance exponentielle, dans le même temps où le coût du stockage des données a, quant à lui, chuté très rapidement, surtout au cours des 25 dernières années. Le graphique suivant illustre la conjugaison de ces deux processus.
Progrès technologique dans la capacité de stockage des données

Source : Thomas Hauet, maître de conférences à l'Université de Lorraine
Selon Thomas Hauet, maître de conférences à l'Université de Lorraine, le stockage des données a énormément évolué depuis le premier disque dur dans les années 1950 (le RAMAC d'IBM en 1956 était une boîte volumineuse de cinquante disques qui faisaient jusqu'à 60 centimètres de large). On n'avait alors que seulement 5 mégabytes d'information avec un coût considérable du gigabyte (10 9 informations) de l'ordre de 10 millions de dollars . En 1981, l'objet disque dur fait 30 à 40 centimètres de large avec des coûts moindres (100 000 dollars du gigabyte), des vitesses un peu plus grandes d'accès à l'information (20 Mbit/s). En 1994, la structure du disque rejoint celle que nous connaissons aujourd'hui, avec un coût de 100 dollars par gigabyte. En 2015, les disques durs permettaient de stocker 4 000 gigabytes d'information avec des densités nettement plus grandes (500 Gbit/inch carré) et des coûts de 0,04 dollar le gigabyte . Nous sommes donc passés en 50 ans d'un coût de 10 millions de dollars à 0,04 dollar le gigabyte.
Avec la vitesse de calcul des processeurs, dont il sera question plus loin, les données massives (« big data ») ont conduit dans la période récente à d'importantes améliorations dans l'efficacité des algorithmes . Mais ces données massives n'ont pas été par elles-mêmes le seul facteur de progression des algorithmes dans les années 2000 et 2010, mais la constitution de grandes bases de données labellisées a souvent constitué un préalable 77 ( * ) .
En 1998, MNIST a fait figure de pionnier en utilisant les images des données postales manuscrites de la poste américaine. Deux autres bases de données labellisées ont plus récemment permis aux développeurs d'entraîner, de faire progresser et de comparer leurs algorithmes. En 2009, l'Institut canadien de recherche avancée, basé à Toronto, a créé les bases de données CIFAR-10 et CIFAR-100 du nom de l'acronyme anglais de l'Institut, Canadian Institute for Advanced Research ou CIFAR. La distinction entre les deux bases de données, vient du nombre de classes utilisées pour l'apprentissage : 10 classes de données pour CIFAR-10 ou 100 classes de données pour CIFAR-100.
En 2010, le projet ImageNet a été lancé aux États-Unis 78 ( * ) avec l'idée d'organiser un concours annuel sur les programmes mis en place pour traiter la base de données éponyme. Ce concours s'intitule ImageNet Large Scale Visual Recognition Challenge (ILSVRC) et rassemble plus de 50 organisations participant chaque année (universités, centres de recherche, entreprises...). En 2016, la base de données avait annoté un total de dix millions d'images disponibles sur Internet .
Dans un article de 2014, Geoffrey Hinton indiquait que la base de données d'apprentissage de Google comprenait alors environ 100 millions d'images annotées et plus de 18 000 classes. En d'autres termes, selon Jean-Claude Heudin prenant l'exemple de la reconnaisance d'un chat, « il vaut mieux avoir des images avec le chat dans tous ses états, plutôt que d'appliquer des prétraitements pour repositionner le chat dans une position idéale », de même pour améliorer les performances d'une application, il vaut donc mieux augmenter le volume des données d'apprentissage que chercher à tout prix un meilleur algorithme, d'où l'aphorisme : « ce n'est pas forcément celui qui a meilleur algorithme qui gagne, c'est celui qui a le plus de données ».
Les données sont donc essentielles car l'apprentissage des algorithmes repose sur celles-ci . L'acquisition de données annotées représente un enjeu stratégique pour les États et un enjeu industriel pour les entreprises.
Ces dernières, telles Google ou Facebook, donnent d'ailleurs maintenant assez largement accès à leurs logiciels en open source , mais - à ce stade - pas à leurs données. La réflexion sur l'open source est importante mais doit aller jusqu'à poser la question de l'accès aux données . Pour Stéphane Mallat, professeur à l'École normale supérieure et rencontré par vos rapporteurs, pour donner des résultats satisfaisants, « ces algorithmes (de deep learning) doivent tout d'abord être alimentés par des quantités de données gargantuesques. C'est pour cela que DeepMind, le projet de Google, possède aujourd'hui une telle longueur d'avance ». Les grandes firmes américaines disposent en effet de données personnelles massives, qu'elles peuvent utiliser librement dans leurs projets de recherche internes. Mais l'étendue des corpus de données ne fait pas tout : « pour les applications médicales, il ne suffit pas d'avoir à disposition un grand nombre de mesures par patients : encore faut-il qu'elles portent sur beaucoup de personnes différentes. Sinon, la règle construite par l'algorithme fonctionnera peut-être très bien pour une personne donnée... mais sera difficilement généralisable à toute la population. La médecine serait le champ de recherche le plus propre à bénéficier des big data... mais c'est celui qui est le plus entravé par les problématiques de confidentialité des données ». Volume, variété, vélocité et véracité sont bien les quatre V complémentaires du big data selon la formule consacrée déjà rappelée par vos rapporteurs.
Les techniques d'apprentissage automatique , ou machine learning , se renforcent au cours des quinze dernières années, surtout au cours des cinq dernières années en bénéficiant du concours de données massives ou big data . Sans que d'importantes nouveautés théoriques n'aient émergé, à l'exception de l'apprentissage profond ou deep learning , les outils de l'intelligence artificielle se sont largement diffusés, aussi bien dans la vie quotidienne que dans des applications industrielles ou militaires. Il convient de relever que nous ne disposons d'aucune explication théorique des raisons pour lesquelles les réseaux de neurones fonctionnent, c'est-à-dire donnent, dans un certain nombre de domaines, d'excellents résultats. Sans disposer d'une démonstration générale, il est cependant possible, selon Bertrand Braunschweig, de comprendre pourquoi ces technologies sont mathématiquement efficaces, et ce grâce à des approximateurs universels parcimonieux ou par la théorie de la dimension de Vapnik et Chervonenkis (dite « VC-dimension »).
En apprentissage profond, qui repose donc sur des réseaux de neurones profonds ( deep neural networks ), on peut distinguer les technologies selon la manière particulière d'organiser les neurones en réseau : les réseaux peuvent être en couches , tel le Perceptron, les Perceptrons multicouches et les architectures profondes (plusieurs dizaines ou centaines de couches), dans lesquels chaque neurone d'une couche est connecté à tous les neurones des couches précédentes et suivantes (c'est la structure la plus fréquente), les réseaux totalement interconnectés , dans lesquels tous les neurones sont connectés les uns aux autres (cas rare des « réseaux de Hopfield » et des « machines de Boltzmann »), les réseaux neuronaux récurrents et les réseaux neuronaux à convolution .
Ces deux dernières technologies, imaginées à la fin des années 1980 et au début des années 1990, font l'objet d'investigations particulièrement poussées et d'applications de plus en plus riches depuis trois ans.
Les réseaux neuronaux récurrents (RNR ou recurrent neural networks-RNN en anglais) permettent de prendre en compte le contexte et de relever le défi de traiter des séquences avec des réseaux de neurones (il existe, au moins, un cycle dans la structure du réseau). Au sein de ces RNR, on relève les architectures MARNN (pour Memory-Augmented Recurrent Neural Networks ou réseaux neuronaux récurrents à mémoire augmentée), les architectures LSTM (pour Long Short Term Memory ), les architectures BLSTM (pour Bidirectionnal Long Short Term Memory ), les architectures BPTT (pour BackProp Through Time ), les architectures RTRL (pour Real Time Recurrent Learning ) et les architectures combinées, avec par exemple des modèles de Markov 79 ( * ) à états cachés (MMC, ou Hidden Markov Model, HMM en anglais). Ces RNR, notamment les LSTM et les MARNN, forment un chantier de recherche prioritaire pour les chercheurs de Google (DeepMind en particulier), Baidu, Apple, Microsoft et Facebook. Leur utilisation pour la traduction, la production de légendes pour les images et les systèmes de dialogues vise à répondre à la question de la capacité à apprendre des tâches qui impliquent non seulement d'apprendre à se représenter le monde, mais aussi à se remémorer, à raisonner, à prédire et à planifier. L'apprentissage par renforcement recourt de plus en plus à ces RNR, notamment en combinaison avec des algorithmes génétiques qui permettent de mieux les entraîner. Les LSTM peuvent aussi faire l'objet d'améliorations avec les SVM.
Les réseaux neuronaux à convolution (RNC) appelés aussi réseaux de neurones profonds convolutifs ( convolutional deep neural networks ou CNN) sont inspirés des processus biologiques du cortex visuel des animaux . En effet, les neurones de cette région du cerveau sont arrangés de sorte qu'ils correspondent à des régions qui se chevauchent lors du pavage 80 ( * ) du champ visuel et transforment un problème global à résoudre en une succession d'étapes plus petites et plus faciles à résoudre : le motif de connexion entre ces réseaux de neurones artificiels à convolution repose sur un procédé similaire. Les réseaux neuronaux sont ici soumis à un mécanisme de poids synaptiques partagés, qui offre l'intérêt d'une plus grande capacité de généralisation pour moins de paramètres. Destinées en priorité à traiter les images, et trouvant leurs principales applications en reconnaissance d'images et de vidéos, leurs applications sont et seront de plus en plus diversifiées, du traitement du langage naturel aux systèmes de recommandation. L'architecture des RNC comprend des couches de traitement indépendantes dédiées qui vont apprendre les prétraitements de l'image au lieu de les coder 81 ( * ) , afin d'extraire ses caractéristiques et de les transmettre à un réseau neuronal plus classique qui effectue la phase de reconnaissance finale, comme l'illustre le graphique suivant.
Architecture d'un réseau de neurones à convolution
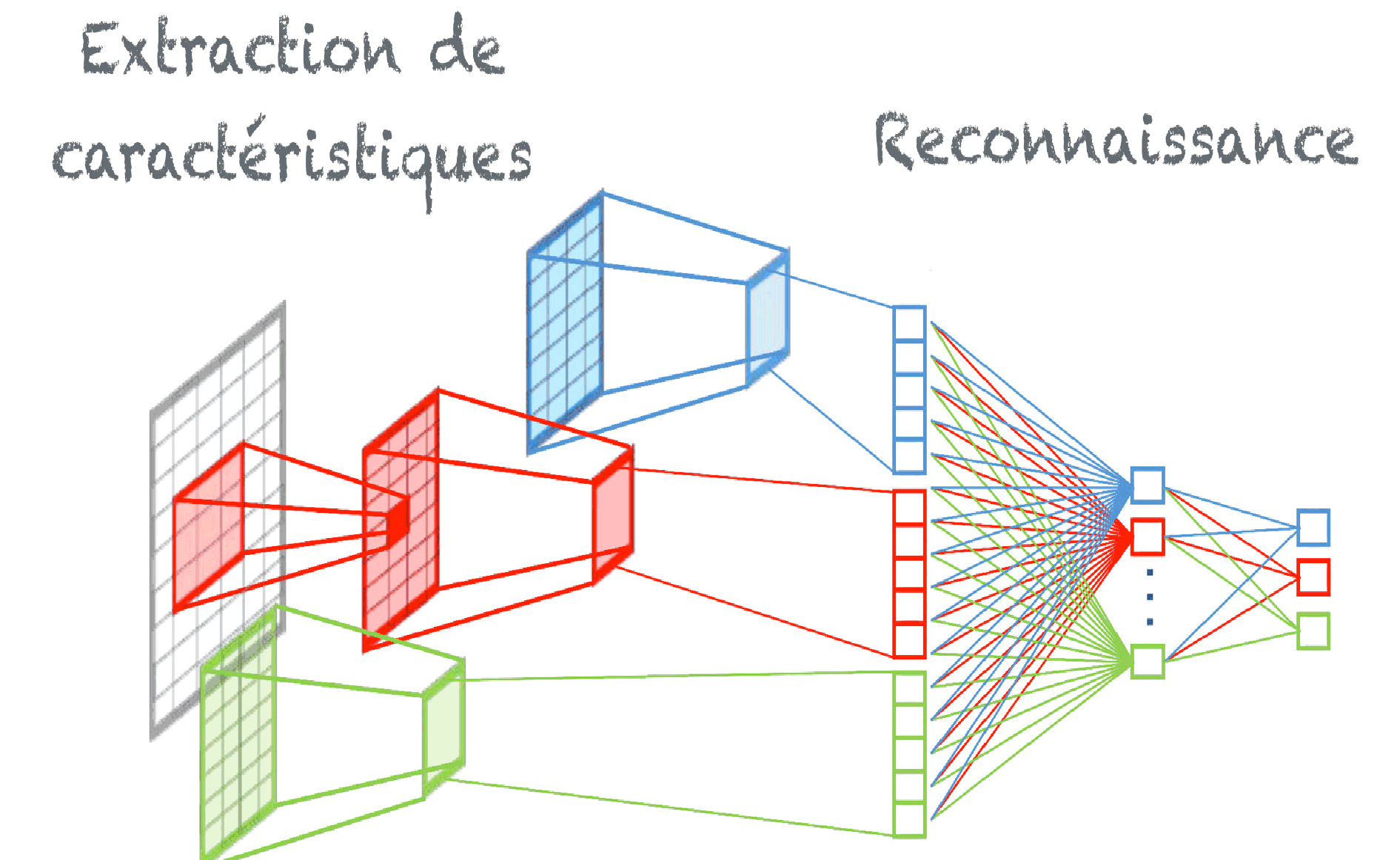
Source : Jean-Claude Heudin, Comprendre le deep learning.
Une autre façon de décrire l'approche par RNC est de la voir comme une décomposition hiérarchisée du processus de reconnaissance , où chaque couche participe à la création de représentations de plus en plus abstraites et conceptuelles.
Visualisation des caractéristiques extraites par chaque couche d'un réseau de neurones à convolution

Source : Jean-Claude Heudin, Comprendre le deep learning.
En outre, il convient de relever qu'au mois de janvier 2017, plusieurs chercheurs travaillant pour le projet de recherche de deep learning « Google Brain » ont publié un article 82 ( * ) présentant les résultats de leurs travaux sur un nouveau modèle de réseau de neurones multicouches (appelé « MoE » pour « Mixture of Experts Layer »). La capacité d'un réseau neuronal monocouche à absorber les données massives étant limitée par son nombre de paramètres calculables, le modèle « MoE » représente un réseau neuronal géant, composé de plusieurs sous-réseaux neuronaux disposés en couches, permettant de traiter les quantités massives de données dont disposent les grandes entreprises du secteur. Accumuler les capacités de plusieurs systèmes experts à travers des réseaux neuronaux, permet de muscler la mémoire du modèle, réduisant ainsi le temps de formation du système et améliorant de manière considérable sa performance et sa capacité de calcul conventionnel, avec une architecture de modèle comprenant jusqu'à 137 milliards de paramètres . Si, à ce stade, le modèle « MoE » est appliqué aux tâches de modélisation des langues et de traduction automatique, cette avancée présentée permet d'entrevoir des progrès exponentiels en matière d'intelligence artificielle, et selon les chercheurs du projet Google Brain le possible avènement d'une intelligence artificielle générale composée de milliers de sous-réseaux et traitant toutes sortes de données. Il s'agit aussi de réduire le nombre de processeurs (GPU) nécessaires à l'apprentissage et donc d'accélérer la capacité du système d'intelligence artificielle à processeur égal 83 ( * ) .
En mars 2017, la publication d'un autre article 84 ( * ) de James Kirkpatrick basé sur l'apprentissage de plusieurs jeux Atari par un système d'IA trace la voie de futurs progrès dans la capacité des réseaux de neurones artificiels à se souvenir de leurs tâches et de leurs expériences précédentes et, donc, à se doter progressivement des éléments constitutifs d'une mémoire. En avril 2017, en utilisant aussi plusieurs jeux Atari, des chercheurs de Google-Deep Mind ont conceptualisé l'apprentissage profond par renforcement 85 ( * ) qui pourrait être selon eux la méthode d'apprentissage la plus rapide , avec l'idée de pouvoir transposer le processus d'apprentissage du système d'IA dans l'environnement réel . Les équipes de cette entreprise sont donc largement mobilisées pour construire des systèmes capables d'approcher l'apprentissage humain 86 ( * ) .
L'essor de l'intelligence artificielle avec le deep learning est, par ailleurs, facilité par la croissance exponentielle des avancées technologiques matérielles dans ce secteur , en particulier les vitesses de calcul des processeurs, appelée aussi « loi de Moore ».
La « loi de Moore » est une conjecture , et donc en réalité une supposition, concernant l'évolution de la puissance de calcul des ordinateurs et, plus généralement, la complexité du matériel informatique. En 1965, Gordon Moore, ingénieur chez Fairchild Semiconductor, un des trois fondateurs d'Intel, constate que depuis 1959 la complexité des semi-conducteurs d'entrée de gamme a doublé tous les ans à coût constant.
Il s'agit donc d'une loi relative au développement exponentiel des capacités de traitement de l'information en vertu d'un doublement constaté pour le même coût, depuis une quarantaine d'année, du nombre de transistors des microprocesseurs sur une puce de silicium . L'observation empirique, ainsi que l'illustre le graphique suivant, démontre que ce doublement a en fait lieu tous les dix-huit mois .
La loi de Moore rapportée à
l'évolution réelle
du nombre de transistors dans les
microprocesseurs
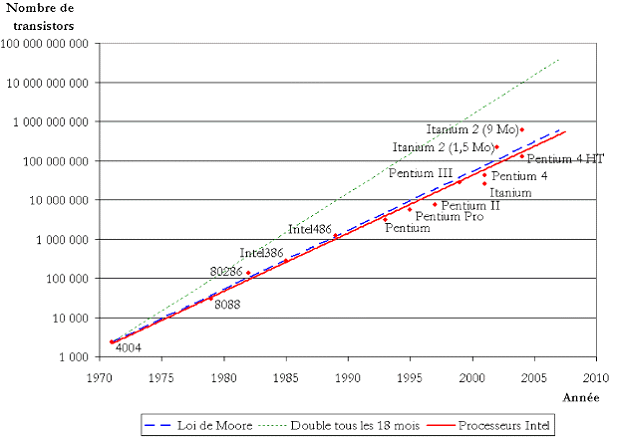
Source : contributeur « QcRef87 », licence de documentation libre
Cette conjecture, connue sous le nom de loi de Moore, est le fondement sur lequel se reposent certains spécialistes pour fixer l'avènement de l'intelligence artificielle forte en 2030. Or, vos rapporteurs rappellent que la conjecture n'a trait qu'aux capacités de calcul et de stockage de données informatiques , elle n'est donc pas de nature à garantir ou à permettre une prévision de la future date de naissance d'une intelligence artificielle égale à celle de l'homme, contrairement à ce que certains font valoir .
Ils notent, par ailleurs, que le deep learning a largement profité des processeurs graphiques dédiés (GPU), souvent issus des exigences des joueurs de jeux vidéo. À la différence des processeurs principaux traditionnels (CPU) aux fréquences d'horloge élevées, les GPU possèdent de nombreux coeurs (unités de calcul), composants parfaitement adaptés aux traitements parallélisables de données de grande dimension .
L'intelligence artificielle, dont certaines des technologies recourent à des analyses qui multiplient les matrices et les convolutions (cas des RNC et des RNR), a donc profité, au cours des dernières années, de ces processeurs graphiques plus efficaces.
La loi de Moore devrait, à technologie égale, atteindre les limites des capacités des puces en silicium . Il semble en effet difficile d'écrire à terme sur des surfaces plus petites que la taille de l'atome . L'avenir de l'accélération des vitesses des processeurs pourrait donc dépendre des innovations futures en informatique quantique ou, encore, des inventions en matière de processeurs fondés sur l'optique . La start-up française LightOn créée par Igor Carron, co-fondateur du Paris Machine Learning Meetup , poursuit ses recherches dans ce sens.
À ce stade du rapport, il semble utile de récapituler par une chronologie les principales étapes et découvertes en intelligence artificielle.
|
Chronologie des principales étapes et
découvertes
330 avant J.-C. : Invention par Euclide de l'algorithme de calcul du plus grand diviseur commun de deux nombres entiers ; 833 : Le mathématicien Al-Khawarizmi, dont les travaux fondent l'algèbre, invente des méthodes précises de résolution des équations du second degré, qui seront appelées algorithmes. Son nom latinisé est à l'origine du mot « algorithme » ; 1694 : Leibniz construit la première machine à calculer ; 1780 : Invention d'une machine à parler par l'abbé Mical et Christian Gottlieb Kratzenstein ; 1834 : Invention par Charles Babbage du premier « ordinateur », sous la forme d'une « machine à différences » inspirée des machines à tisser ; 1847 et 1854 : Premières mathématisations de la logique par Georges Boole ; 1869 : Création de pianos mécaniques capables de raisonner par William Stanley Jevons ; 1936 : Formulation des fondements théoriques de l'informatique par Alan Turing (son appareil sera plus tard appelé « machine de Turing ») par l'introduction des concepts de programme et de programmation ; 1943 : Premier article sur le potentiel des réseaux de neurones artificiels par Warren McCulloch et Walter Pitts ; 1950 : Invention du « test de Turing » en vue d'évaluer l'intelligence d'un ordinateur par rapport à celle d'un être humain ; 1956 : Invention, en tant que discipline et en tant que concept, de l'intelligence artificielle lors de la conférence de Dartmouth par John McCarthy et Marvin Minsky ; 1957 : Invention du perceptron, première utilisation de réseaux de neurones artificiels modélisés, par Frank Rosenblatt ; 1958 : Invention du langage de programmation Lisp ; 1965 : Formulation par Gordon Moore de la loi qui porte son nom concernant le doublement de la vitesse de calcul des ordinateurs tous les 18 mois à coût constant ; 1966 : Invention par Joseph Weizenbaum du premier agent conversationnel « Eliza » ; 1974 : Invention du premier système expert, dit « Mycin » ; 1986 : Invention des perceptrons multicouches par Yann LeCun et David Rumelhart et de la rétropropagation du gradient par David Rumelhart, Geoffrey Hinton et Ronald Williams ; 1997 : Victoire du système Deep Blue aux échecs face à Garry Kasparov ; Années 2000 et 2010 : Conjugaison efficace des technologies de deep learning avec l'émergence des données massives et l'accélération marquée de la vitesse de calcul des processeurs ; Années 2010 : Les réseaux neuronaux récurrents (RNR) et les réseaux neuronaux à convolutions (RNC), imaginés dès la fin des années 1980, font l'objet d'usages particulièrement remarqués ; 2011 : Victoire du système Watson au jeu télévisé Jeopardy en 2011 ; 2016 : Victoire du système AlphaGo au jeu de Go face au champion Lee Sedol. 2017 : Victoire du système Libratus au cours d'une partie de poker de 20 jours face à quatre joueurs professionnels Source : OPECST |
3. Les technologies d'intelligence artificielle conduisent, d'ores et déjà, à des applications dans de nombreux secteurs
Les applications sectorielles présentes ou futures sont d'envergure considérable, que l'on pense par exemple aux transports, à l'aéronautique, à l'énergie, à l'environnement, à l'agriculture, au commerce 87 ( * ) , à la finance, à la défense , à la sécurité, à la sécurité informatique, à la communication, à l'éducation, aux loisirs, à la santé, à la dépendance ou au handicap . Souvent, la capacité prédictive de ces technologies se trouve mobilisée.
Il s'agit d'autant de jalons d'applications sectorielles. Car en réalité, derrière le concept d'intelligence artificielle, ce sont des technologies très variées, en constante évolution, qui donnent lieu à des applications spécifiques pour des tâches toujours très spécialisées .
Applications des technologies d'intelligence artificielle en France
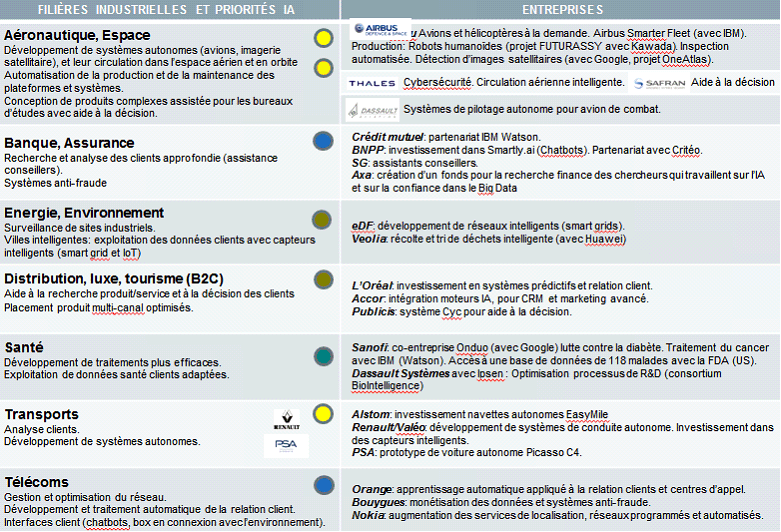
Source : Gouvernement
Les applications dans le secteur financier, en particulier les banques et les assurances , sont nombreuses. La moitié du volume des transactions financières et 90 % des ordres résultent de l'activité d'algorithmes . Du tiers des échanges boursiers en Europe en 2010, ce taux a dépassé les 90 % depuis 2012.
Depuis 2012, IBM détient un brevet l'autorisant à procéder à une estimation de la volatilité des transactions à haute fréquence.
Le sujet du « high frequency trading » (HFT) ou trading à haute fréquence (THF) constitue un questionnement en soi, sur lequel la commission des Finances du Sénat a commencé à travailler 88 ( * ) .
|
L'intelligence artificielle et les technologies financières (« Fintech ») Le renouveau de l'intelligence artificielle est permis par une accélération spectaculaire des investissements, notamment de la part des grands acteurs industriels et du capital-risque, ainsi que par les progrès conséquents des performances d'intelligence artificielle visibles, notamment, dans le développement de la reconnaissance d'images, de la parole et de la traduction. Les technologies d'intelligence artificielle sont souvent produites à l'extérieur des entreprises : la compétence primordiale que doivent acquérir les entreprises est d'intégrer le flux permanent de ces technologies quand elles n'en sont pas directement productrices. Plus précisément, les technologies financières ( Fintech ) permettent par exemple d'utiliser l'intelligence artificielle pour des applications d'interaction avec les clients, de tri dans la proposition de contrats et de détection de fraude dans le traitement des demandes. L'intelligence artificielle développée par de nombreuses entreprises émergentes est tournée vers le client. Ces systèmes d'intelligence artificielle visent à toucher toutes les difficultés relationnelles que peuvent avoir les entreprises. Les technologies modernes de chatbot sont mises au service du client. Les algorithmes peuvent être connus car souvent en open source, cependant, c'est le savoir-faire des ingénieurs et des développeurs qui leur donnent leur complexité. Source : Intervention de M. Yves Caseau, animateur du groupe de travail sur l'IA de l'Académie des Technologies, lors de la journée « Entreprises françaises et intelligence artificielle » organisée par le MEDEF et l'AFIA le 23 janvier 2017 |
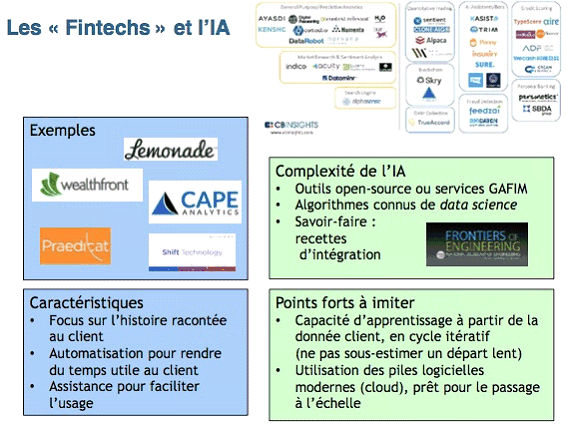
Source : groupe de travail sur l'IA de l'Académie des Technologies animé par Yves Caseau
Concernant le secteur automobile , le logiciel n'a, pendant longtemps, représenté qu'une fraction très réduite de la valeur d'un véhicule, il s'agissait, il y a dix ans, de 3 %, aujourd'hui, il s'agit de 10 % et il pourrait s'agir de l'ordre de 15 % ou 30 % demain. Tesla annonce qu'il produira 500 000 voitures autonomes d'ici à 2020.
Les constructeurs français se sont eux aussi engagés dans la voiture autonome, à l'image de PSA qui a présenté son prototype « Peugeot Instinct » au salon de Genève en mars 2017 et qui a signé de nombreux partenariats à ce sujet, ainsi que l'a fait son concurrent Renault , qui accompagne ce développement industriel d'une démarche éthique intéressante sur la protection des données selon une approche Privacy by design (respect de la vie privée dès le stade de la conception) et a à cette fin élaboré un pack de conformité avec la CNIL. L'entreprise a ainsi joué un rôle moteur dans la charte de constructeurs élaborée au sein de l'association des constructeurs européens d'automobiles.
On peut relever qu'Uber dispose d'un centre de recherche à Pittsburgh, fondé en partenariat avec l'Université Carnegie-Mellon, consacré aux véhicules sans conducteurs. Quatre prototypes y sont testés par Uber depuis septembre 2016. Les quinze employés de Geometric Intelligence, racheté par Uber, qui sont des universitaires et des scientifiques, se trouvent désormais affectés à ces recherches.
|
L'intelligence artificielle, levier de progrès pour l'industrie automobile L'industrie automobile est mobilisée pour réussir trois révolutions, chacune d'elles suffisant pour la transformer en profondeur : la voiture électrique (ce qui impliquera des réseaux électriques intelligents ou smart grids ), la voiture connectée (l'intelligence artificielle permet ici de gérer et d'exploiter les données, ou de mettre à disposition des consommateurs des assistants virtuels) et la voiture autonome . Ces trois révolutions sont concomitantes et doivent être gérées par l'industrie. Elles nécessitent que l'industrie automobile maîtrise des technologies qui ne la concernaient pas jusqu'il y a peu. Pour être davantage autonome, la voiture développe son intelligence. L'aide à la conduite et l'autonomisation de la conduite d'un véhicule suivent trois étapes :
Ces étapes sont celles qui guident la conduite humaine. Percevoir l'environnement est complexe et dépend de la photographie renvoyée par ce que perçoit une caméra automobile. Il faut assurer un équilibre entre la performance du système et la robustesse de ce système. D'un point de vue de l'analyse d'image, la perception est complexe pour un système autonome. Il existe une véritable rupture entre une aide à la conduite dans laquelle le conducteur reste maître et une voiture autonome où la conduite est déléguée. Cette rupture technologique implique la fabrication de très nombreux scénarios. L'intelligence artificielle permet de gérer des scénarios très diversifiés et d'entrer dans une phase d'apprentissage. L'intelligence artificielle contribuera à la transformation de l'industrie automobile. L'ensemble des constructeurs investissent dans l'intelligence artificielle, soit en créant leurs propres laboratoires de recherche, soit en établissant des contrats avec des laboratoires existants. L'intégration de l'intelligence artificielle dans l'industrie automobile impliquera un changement des modèles d'affaires des entreprises du secteur. Le caractère crucial de l'intelligence artificielle pour le secteur automobile réside dans le fait que sa maîtrise permettra de développer des applications d'un bout à l'autre de la chaîne de production , de la conception des logiciels et des véhicules jusqu'au service après-vente. La maîtrise de l'intelligence artificielle représente donc un enjeu essentiel pour les constructeurs automobiles. Source : intervention de Patrick Bastard, directeur de l'ingénierie et des technologies électroniques chez Renault, lors de la journée « Entreprises françaises et intelligence artificielle » organisée par le MEDEF et l'AFIA le 23 janvier 2017 |
En lien avec l'intelligence artificielle, la robotique va connaître un essor inédit. Selon certaines prévisions récentes, le marché de la robotique devrait ainsi atteindre 35 millions de robots vendus d'ici à 2018 89 ( * ) , sachant qu'environ 1,5 million sont aujourd'hui en fonctionnement. Le syndicat de la robotique (SYROBO) établit des prévisions du même ordre, puisqu'il estime que 31 millions de robots - industriels et personnels - pourraient être vendus dans le monde entre 2014 et 2017. La croissance mondiale de ce marché serait d'environ 10 % par an en moyenne sur dix ans à partir de 2016, selon le Boston Consulting Group (BCG), au lieu de 2 % par an jusqu'en 2014. La seule robotique de service représente à elle seule un énorme gisement de croissance : le marché est estimé à environ 100 milliards d'euros à l'horizon 2020 par la Commission européenne, soit une multiplication par 30 en dix ans. La France se place au troisième rang mondial dans la recherche fondamentale en robotique derrière les États-Unis et le Japon, ce qui témoigne d'un avantage comparatif à consolider. Nao, Pepper ou Romeo ont été conçus par Aldebaran, entreprise française basée à Issy-les-Moulineaux, rachetée en 2012 par SoftBank Robotics, leader mondial de la robotique humanoïde. Buddy est un autre robot de service créé par l'entreprise française Bluefrog et dont la commercialisation en 2017 a été annoncée l'année dernière pour moins de 1 000 euros. La société française Robosoft a annoncé en 2016 le lancement de la seconde version de son robot Kompaï , conçu pour assister les personnes âgées au quotidien. D'autres robots existent sur le marché mondial et peuvent être mentionnés comme Paro, Jibo, Asimo, Amazon Echo, Otto, Floka ...
Les capacités des agents conversationnels dits chatbots ou même bots sont, il est vrai, encore limitées mais ces derniers vont rendre de plus en plus de services à leurs utilisateurs . Le cabinet d'études Forrester estime, d'ailleurs, que les bots ne sont pas encore à la hauteur des attentes des usagers. Laurence Devillers explique ainsi qu'ils n'ont pas de mémoire, qu'ils se contentent de suivre des scénarios de questions-réponses et qu'ils ne savent pas répondre aux utilisateurs qui se plaignent de dépression ou de maladies physiques. Vos rapporteurs ont constaté qu'en dépit de leur absence de mémoire, les bots font déjà un excellent travail en matière de prévention du suicide en réagissant à certains mots clés, ainsi que l'a expliqué et démontré in vivo à vos rapporteurs Alex Acero, directeur du projet Siri chez Apple. Siri reçoit par exemple 5 000 propos suicidaires par jour qu'il traite en rassurant le propriétaire du téléphone et en orientant vers des services spécialisés. Cortana de Microsoft gère ce type de conversations avec la même efficacité. Ces exemples sont un premier niveau de gestion de la dépression ne nécessitant pas de mémoire dans les systèmes d'IA.
Vos rapporteurs ont pu tester en situation ces usages bénéfiques pour la société des agents conversationnels . Il ne s'agit que d'un exemple, leur utilité sera bien plus diverse en pratique, surtout quand les machines amélioreront leurs capacités en termes de mémoire. Au salon professionnel E-commerce One To One 2017 90 ( * ) , Google a invité à s'extraire du modèle du moteur de recherche tel que nous le connaissons encore aujourd'hui pour entrer dans l'ère de l'assistance, « The age of assistance » était ainsi le nom de sa présentation 91 ( * ) .
En matière d' éducation , les perspectives pour l'intelligence artificielle sont riches mais les applications restent encore rares. Ce point est développé plus loin dans le rapport.
Dans le secteur des loisirs , tels que les jeux vidéos ou le cinéma, l'intelligence artificielle est utilisée assez massivement. Il peut par exemple s'agir de simuler des foules grâce à des systèmes multi-agents, comme dans les trilogies Le Seigneur des anneaux et Le Hobbit . Les jeux sérieux 92 ( * ) , ou s erious games en anglais, tout commes les visites virtuelles 93 ( * ) pourront de plus en plus mobiliser des technologies d'IA.
Les secteurs de l'énergie et de l'environnement commencent à recourir à des solutions fondées sur l'intelligence artificielle. Les compteurs intelligents sont une des pistes visibles de cette évolution en cours, sur laquelle travaille l'OPECST. L'IA permet de modéliser et de simuler et est donc utilisée en météorologie, sismologie, océanographie, planétologie ou, encore en urbanisme. Le GIEC a recours à ces technologies pour analyser les changements climatiques.
L'agriculture peut aussi être citée , car ce secteur présente des usages divers et des possibilités nombreuses. Les applications concernent la gestion des exploitations mais vont bien au-delà. Le graphique suivant décrit ainsi les cycles de traitement des données dans l'agriculture. À chaque étape, l'intelligence artificielle peut jouer un rôle de plus en plus grand.
Les processus de traitement des données dans l'agriculture
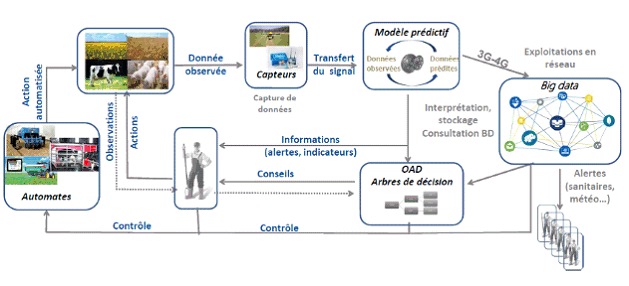
Source : INRA
De manière opérationnelle, de nombreuses applications sont possibles dans le secteur agricole , pour l'exploitant (dans le suivi ou la régulation), la filière agricole concernée (en matière de progrès génétiques par exemple) mais aussi l'ensemble de la société (avec le cas des réseaux d'épidémio-surveillance). Le graphique suivant l'illustre.
Exemples d'utilisations des données dans l'agriculture
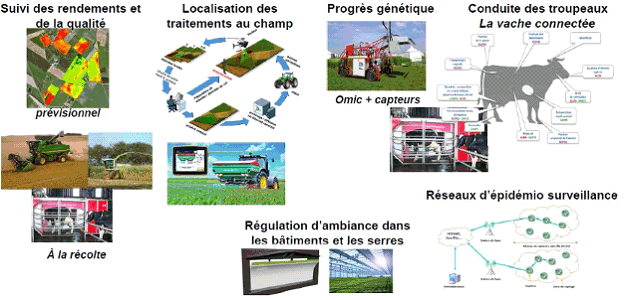
Source : INRA
Il peut être donné l'exemple d'une entreprise qui a ainsi mis au point un système de conteneurs agricoles intelligents, en partenariat avec le MIT Media Lab . À l'intérieur, l'intelligence artificielle contrôle la lumière, l'humidité, la température, mais aussi les nutriments apportés aux plantes, supervisant leur croissance en temps réel. La technologie permet ici d'améliorer l'efficacité du cycle de production, et ce sans avoir recours aux OGM.
Dans le secteur de la défense , les drones autonomes sont de plus en plus utilisés, à l'image de l'expérience des armées australiennes, israéliennes ou, encore, saoudiennes. Ce n'est pas le secteur où le développement de l'intelligence artificielle est le plus souhaitable.
La sécurité est, d'ores et déjà, améliorée avec une intelligence artificielle qui peut détecter les situations anormales (par exemple sur les flux vidéo des caméras de surveillance) et alerter les services compétents.
En matière de sécurité numérique , ce sont les fraudes et les cyberattaques qui peuvent être prévues et gérées de manière plus efficace. La cybersécurité peut être révolutionnée par l'intelligence artificielle. La DARPA a ainsi consacré son grand concours 2016 à ce sujet.
Dans l' assistance au diagnostic ou dans les services de maintenance prédictive dans l'industrie et l'électroménager, l'intelligence artificielle optimise et détecte les défaillances en amont, de même qu'elle prévoit les étapes de réparation.
Les usages de l'intelligence artificielle en matière de technologies médicales , de gestion de la dépendance ou de handicap seront considérables mais ils n'ont pas été au coeur du travail de vos rapporteurs, le sujet a déjà été traité à plusieurs reprises par l'OPECST et continuera à l'être, autour de rapports spécifiques. Le dernier exemple remonte à 2015 avec un rapport consacré au thème « Le numérique au service de la santé » 94 ( * ) . Il est certain que l'intelligence artificielle est et sera de plus en plus utile à la médecine, notamment et y compris à court terme en matière de diagnostic et de dépistage des maladies. Les systèmes recourant à l'IA font de plus en plus souvent aussi bien, voire mieux, que les médecins dans le dépistage du cancer 95 ( * ) .
Quelques cas emblématiques peuvent être mentionnés. En génomique , par exemple pour la validation et la critique des thérapies, outre le deep learning , peuvent être utilisés des systèmes non logiques ou partiellement logiques, des réseaux bayésiens, des systèmes de règles et d'arbres de décision, des systèmes experts... En matière de prédiction du repliage de protéines 96 ( * ) ou de segmentation des IRM du cerveau en vue d'identifier certaines zones, des projets de recherche sont menés avec l'utilisation de l'apprentissage automatique ( machine learning ) et de systèmes multi-agents collaboratifs pour découvrir les règles qui régulent la géométrie spatiale de structures complexes (exemple d'un projet associant l'Université de Grenoble, Inria et l'INSERM). L'utilisation de systèmes multi-agents est également possible pour analyser les courbes de réponse d'assistants respiratoires et détecter les anomalies.
Le Dr Lionel Jouffe, président de Bayesia, s'est spécialisé dans l'utilisation des r éseaux bayésiens pour l'aide à la décision médicale . Il s'agit d'une modélisation des connaissances par apprentissage automatique à partir des données. Le réseau bayésien peut être utilisé pour des applications de différentes natures. Il faut rappeller qu'un réseau bayésien peut ainsi permettre à une entreprise de calculer la probabilité qu'un client soit intéressé par un produit, à une banque ou un business angel de calculer la probabilité de faillite d'une start-up, tout comme il peut être appliqué à la thérapie endovasculaire. Ainsi, les applications diverses d'un réseau bayésien lui permettent d'être utilisé pour de nombreuses tâches, comme l'analyse de leviers d'optimisation, le calcul de scores, l'analyse de défauts par l'optimisation de processus, l'analyse opérationnelle, le diagnostic et le dépannage ou encore l'analyse de risques et la maintenance préventive.
L' exemple de Watson est également instructif, pour le secteur médical et l'aide au diagnostic mais même au-delà. Dévoilé au grand public par IBM en 2011, ce système a affronté, avec succès, des candidats humains au jeu télévisé américain « Jeopardy ! ». En 1996 et 1997, IBM avait déjà prouvé les capacités de son superordinateur Deep Blue en organisant des parties d'échecs contre Garry Kasparov. Nicolas Sekkaki, responsable d'IBM France, assure que sa société est aujourd'hui engagée dans une dizaine de projets faisant appel à Watson sur notre territoire , mais les retours d'expérience dignes de ce nom sur le sujet restent encore peu nombreux. Le Crédit Mutuel teste avec IBM l'utilisation de l'intelligence artificielle et des technologies cognitives depuis juin 2015 et a intégré certaines technologies dans la gestion de sa relation client depuis 2016. Watson est ainsi utilisé pour l'assistance des conseillers dans le traitement des courriels d'une part, et sur les produits d'assurance et d'épargne d'autre part. Une assistance informatisée qui vise à optimiser la productivité du conseiller et améliorer la pertinence des réponses fournies aux clients finaux. Pour l'instant, il ne s'agirait pas de laisser l'intelligence artificielle interagir directement avec le client.
Les progrès dans les domaines de l'intelligence artificielle et de la robotique, en matière de vision par ordinateur , de traitement automatique du langage naturel , de reconnaissance automatique de la parole , ou, encore de bioinformatique , à travers par exemple l'étude de l'ADN, ouvrent encore toute une série de perspectives d' applications fécondes .
Vos rapporteurs relèvent une part d'effet de mode dans l'écosystème entrepreneurial , visible dans le recours à certains concepts, tels que l'intelligence artificielle, le big data , le cloud , l' IoT (Internet des objets), le blockchain . Pour le journaliste Olivier Ezratty, le stéréotype de la start-up en intelligence artificielle serait, de manière caricaturale, une « solution d'agent conversationnel en cloud faisant du big data sur des données issues de l' IoT en sécurisant les transactions via des blockchains ».
Les entreprises de l'intelligence artificielle se diversifient, se reconfigurent et s'absorbent les unes les autres, disparaissent parfois et d'autres entreprises, issues d'autres secteurs, parfois plus traditionnels, tentent de les rejoindre dans une course propre à l'économie des plateformes , que vos rapporteurs décriront plus loin.
4. Par leurs combinaisons en évolution constante, ces technologies offrent un immense potentiel et ouvrent un espace d'opportunités transversal inédit
Le potentiel de ces technologies est immense et ouvre de manière transversale un espace d'opportunités inédit : nos économies peuvent en bénéficier car les champs d'application sont et seront de plus en plus nombreux. Ces technologies sont non seulement en évolution constante, mais leurs combinaisons ouvrent de nouvelles perspectives .
Avec l'explosion des données massives ou big data et l'augmentation des vitesses de calcul (vue plus haut avec la loi de Moore), ces techniques d'intelligence artificielle deviennent de plus en plus puissantes et efficaces , grâce aux combinaisons de compétences et de technologies en particulier.
Les combinaisons et les hybridations entre technologies mises au point par Google Deep Mind vont dans ce sens, en utilisant tant des outils traditionnels comme la méthode Monte-Carlo que des systèmes plus récents comme l'apprentissage profond. L'entreprise fait figure de structure à l'avant-garde de la recherche mondiale en intelligence artificielle. Les combinaisons de technologies d'intelligence artificielle ouvrent un champ de recherche fécond et elle en a fait sa spécialité. Le programme AlphaGo a ainsi appris à jouer au jeu de Go par une méthode de deep learning couplée à un apprentissage par renforcement et à une optimisation selon la méthode Monte-Carlo .
Dans les faits , et comme l'illustrent les cas déjà évoqués de Prolog 97 ( * ) , des réseaux de neurones profonds 98 ( * ) ou du programme AlphaGo 99 ( * ) , l'intelligence artificielle combine très souvent plusieurs techniques .
De plus en plus, les outils d'intelligence artificielle sont systématiquement utilisés conjointement .
Par exemple, les systèmes experts sont utilisés avec le raisonnement par analogie , éventuellement dans le cadre de systèmes multi-agents .
De même, les SVM et l'apprentissage par renforcement se combinent très efficacement avec l'apprentissage profond des réseaux de neurones 100 ( * ) . Ce dernier, le deep learning , peut aussi s'enrichir de logiques floues ou d'algorithmes génétiques et trouve de nombreuses applications dans le domaine de la reconnaissance de formes (lecture de caractères, reconnaissance de signatures, de visages, vérification de billets de banque), du contrôle de processus et de prédiction.
Selon Stéphane Mallat, professeur à l'École normale supérieure, le deep learning représente en tout cas « une rupture non seulement technologique, mais aussi scientifique : c'est un changement de paradigme pour la science ». Traditionnellement, les modèles sont construits par les chercheurs eux-mêmes à partir de données d'observation, en n'utilisant guère plus de dix variables alors que « les algorithmes d'apprentissage sélectionnent seuls le modèle optimal pour décrire un phénomène à partir d'une masse de données » et avec une complexité inatteignable pour nos cerveaux humains, puisque cela peut représenter jusqu'à plusieurs millions de variables . Alors que le principe de base de la méthode scientifique réside dans le fait que les modèles ou les théories sont classiquement construits par les chercheurs à partir des observations, le deep learning change la donne en assistant l'expertise scientifique dans la construction des modèles. Stéphane Mallat remarque également que la physique fondamentale et la médecine (vision, audition) voient converger leurs modèles algorithmiques.
Denis Girou, directeur de l'Institut du développement et des ressources en informatique scientifique au CNRS, estime que « la science a pu construire des modèles de plus en plus complexes grâce à l'augmentation de la puissance de calcul des outils informatiques, au point que la simulation numérique est désormais considérée comme le troisième pilier de la science après la théorie et l'expérience ». En sciences du climat par exemple, l'approche traditionnelle qui consiste à injecter les mesures issues de capteurs, en tant que conditions initiales des simulations, s'est enrichie : les approches big data avec le machine learning et l'analyse statistique des données ouvrent ainsi une nouvelle voie : « ce qu'on appelle « climate analytics » a permis aux climatologues de découvrir, grâce au travail de statisticiens, de nouvelles informations dans leurs données ». Il s'agit d'outils sur lesquels s'appuie notamment le Groupe d'experts intergouvernemental sur l'évolution du climat (GIEC) dans ses prédictions sur le réchauffement climatique.
Vos rapporteurs appellent à la vigilance à l'égard de l'illusion du « jamais vu », il faut en effet relativiser la nouveauté de l'aide apportée par l'intelligence artificielle, la découverte d'autres outils complexes ayant jalonné l'histoire des civilisations humaines. Dans un texte intitulé « L'ordinateur et l'intelligence » 101 ( * ) , l'économiste Michel Volle rappelle ainsi que « des machines remplacent nos jambes (bateau, bicyclette, automobile, avion), des prothèses assistent nos sens (lunettes, appareils acoustiques, téléphones, télévision). L'élevage et l'agriculture pratiquent la manipulation génétique, depuis le néolithique, par la sélection des espèces. La bionique, l'intelligence artificielle ne font que s'ajouter aujourd'hui au catalogue des prothèses qui assistent nos activités physiques ou mentales ».
Toutefois, quand bien même l'illusion du jamais vu doit être dénoncée , il convient d' éviter aussi l'écueil du toujours ainsi . L'intelligence artificielle représente une série d'outils à l'autonomie croissante, qui offre de nouvelles opportunités et qui pose de nombreuses questions. La complémentarité homme-machine est l'une de celles-ci, avec les potentialités d'amplification de l'action et d'amélioration de l'efficacité offertes par l'intelligence artificielle.
5. L'apprentissage automatique reste encore largement supervisé et fait face au défi de l'apprentissage non supervisé
Selon Yann LeCun, le défi scientifique auquel les chercheurs doivent s'atteler , au-delà de la redécouverte de ces deux techniques, c'est celui de l'apprentissage non supervisé alors que l'apprentissage machine reste le plus souvent supervisé : on apprend aux ordinateurs à reconnaître l'image d'une voiture en leur faisant absorber des milliers d'images et en les corrigeant quand ils font des erreurs d'interprétation. Or les humains découvrent le monde de façon non supervisée. Un enfant reconnaît ses proches très vite et distingue rapidement un lion d'un chat, sans apprentissage supervisé etc.
Dans sa leçon inaugurale au Collège de France, Yann LeCun estime ainsi que « tant que le problème de l'apprentissage non supervisé ne sera pas résolu, nous n'aurons pas de machines vraiment intelligentes. C'est une question fondamentale scientifique et mathématique, pas une question de technologie. Résoudre ce problème pourra prendre de nombreuses années ou plusieurs décennies. À la vérité, nous n'en savons rien ». Selon lui, cette technologie, qui peut prendre la forme de l'apprentissage prédictif, devrait permettre aux machines d'acquérir ce que l'on appelle le sens commun.
L'apprentissage non supervisé permettra de faire progresser les algorithmes sans le coût lié à l'étiquetage et à la supervision humaine de l'apprentissage . C'est à l'évidence un défi scientifique , mais vos rapporteurs notent qu'il n'est pas sûr que l'on y parvienne et que les moyens mis en oeuvre doivent rester proportionnés, surtout qu'il n'est absolument pas certain que l'on ainsi puisse parvenir à l'apprentissage non supervisé.
Ils relèvent que les travaux en robotique développementale et sociale de Pierre-Yves Oudeyer, responsable de l'équipe Flowers d'Inria, sont particulièrement féconds : il s'agit, en faisant appel à de nouvelles disciplines connexes (neurosciences et psychologie développementale), de concevoir des algorithmes et des robots capables d'apprendre des choses nouvelles sur le long terme sans l'intervention d'un ingénieur, en combinant curiosité artificielle et interactions sociales avec des humains, selon la maxime « humaniser les machines plutôt que machiniser les hommes » et en visant à reproduire les comportements d'apprentissage des enfants. Vos rapporteurs ont noté l'influence des travaux de Jean Piaget dans ces recherches.
En conclusion de cette partie, vos rapporteurs prennent acte des limites des technologies actuelles d'intelligence artificielle et font valoir que l'intelligence artificielle, qui agit sur la base de ce qu'elle sait, devra relever le défi d'agir sans savoir, puisque comme l'affirmait le biologiste, psychologue et épistémologue Jean Piaget « L'intelligence, ça n'est pas ce que l'on sait, mais ce que l'on fait quand on ne sait pas ».
* 73 Les mathématiciens et neurologues Warren McCulloch et Walter Pitts posent dès 1943 l'hypothèse que les neurones avec leurs deux états, activé ou non activé, pourrait permettre la construction d'une machine capable de procéder à des calculs logiques. Ils publièrent dès la fin des années 1950 des travaux plus aboutis sur les réseaux de neurones artificiels.
* 74 Cf. « The Perceptron : A Probabilistic Model for Information Storage and Organization in the Brain ».
* 75 http://www.nature.com/nature/journal/v323/n6088/abs/323533a0.html
* 76 Elle apparait pour la première fois en 1977 dans l'ouvrage The Theory of Affordances puis en 1979 dans Approche écologique de la perception visuelle, écrits par le psychologue James J. Gibson. Il s'agit, selon lui, de combinaisons invariantes de variables qui dépendent du contexte de l'action : les affordances ne sont donc pas des propriétés à part entière de l'objet dans ses travaux. La perception dépendant de la culture, de l'expérience et de l'apprentissage, une affordance dissimulée peut devenir perceptible par l'apprentissage. En outre, les normes peuvent contribuer à la perception des affordances . Le sens du concept a évolué et s'est élargi aux capacités d'un objet ou d'un être à suggérer sa propre utilisation.
* 77 Une liste de ces nombreuses bases de données peut être consultée ici : https://en.wikipedia.org/wiki/List_of_datasets_for_machine_learning_research
* 78 Avec des chercheurs tels que Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg ou Fei-Fei Li. Site : http://image-net.org/
* 79 En mathématiques, un processus de Markov (la théorie des probabilités parle plutôt de « processus de décision markovien ») est une chaîne stochastique possédant la propriété de Markov qui réside dans le fait que la prédiction du futur à partir du présent n'est pas rendue plus précise par des éléments d'information concernant le passé. L'agent prend dans ce cas des décisions avec un résultat aléatoire de ses actions. Claude Shannon s'en est inspiré en 1948 pour fonder sa théorie de l'information et l'algorithme de classement par popularité de Google repose notamment sur un modèle de ce type. L'apprentissage par renforcement permet de résoudre le problème des processus markoviens.
* 80 « Paver » l'image de départ revient à la découper en petites zones appelées tuiles. En informatique, chaque tuile est traitée individuellement par un neurone artificiel, qui effectue une opération de filtrage classique en associant un poids à chaque pixel de la tuile. Tous les neurones ont donc les mêmes paramètres, ce qui permet d'obtenir le même traitement pour tous les pixels de la tuile.
* 81 Le fait de coder les pixels est une approche plus traditionnelle de la reconnaissance d'images, dans laquelle l'ensemble des pixels d'une image (exemple 262 544 entrées pour une images de 512x512 pixels) est codé et vectorisé en une couche d'entrée du réseau de neurones.
* 82 Geoffrey Hinton, Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le et Jeff Dean, « Outrageously large neural networks : the sparsely-gated mixture-of-experts layer », janvier 2017, cf. https://arxiv.org/abs/1701.06538
* 83 Cf les explications données à ce sujet par le jeune chercheur Théo Szymkowiak, président de la société pour l'IA de l'université Mc Gill : https://medium.com/@thoszymkowiak/google-brains-new-super-fast-and-highly-accurate-ai-the-mixture-of-experts-layer-dd3972c25663
* 84 Revue de l'Académie américaine des sciences, PNAS, volume 114, issue 13, march 2017 « Overcoming catastrophic forgetting in neural networks », cf. http://m.pnas.org/content/114/13/3521.abstract
* 85 Todd Hester, Matej Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Andrew Sendonaris, Gabriel Dulac-Arnold, Ian Osband, John Agapiou, Joel Z. Leibo et Audrunas Gruslys « Learning from demonstrations for Real World Reinforcement Learning », cf. https://arxiv.org/abs/1704.03732
* 86 Un article du complément scientifique du Guardian va dans ce sens : https://www.theguardian.com/global/2017/mar/14/googles-deepmind-makes-ai-program-that-can-learn-like-a-human
* 87 Le « yield management », qui consiste à faire varier les prix en vue de l'optimisation du remplissage (transport aérien et ferroviaire ou hôtellerie) et/ou du chiffre d'affaires, est déjà connu de chacun de nous. En 2013, à titre d'exemple, Amazon changeait ses prix en moyenne plus de 2,5 millions de fois par jour.
* 88 Cf. Par exemple son rapport n° 369 (2011-2012) sur la proposition de résolution sur la régulation des marchés financiers. Cette proposition, devenue une résolution du Sénat le 21 février 2012, estime « nécessaire de renforcer l'encadrement des pratiques mettant en péril l'intégrité des marchés financiers et notamment les transactions sur base d'algorithmes (trading algorithmique ou trading haute fréquence) », cf. https://www.senat.fr/leg/tas11-079.html
* 89 Cf. www.worldrobotics.org/uploads/tx_zeifr/Executive_Summary__WR_2015.pdf
* 90 Cf. https://www.ecommerce1to1.com/
* 91 Cette économie de l'assistance repose sur trois déterminants principaux : la personnalisation de la relation avec le mobinaute (plus encore que l'internaute), le web sémantique (la question donne lieu à une réponse directement, voire la machine anticipe vos questions) et, enfin, le web vocal (20 % des requêtes formulées aujourd'hui sur Google via un mobile Android sont vocales et ce chiffre devrait dépasser les 50% en 2020). Cf. http://www.frenchweb.fr/google-annonce-la-mort-du-moteur-de-recherche-et-lavenement-de-lage-de-lassistance/286043
* 92 Pour Julian Alvarez et Olivier Rampnoux, cinq types de jeux sérieux peuvent être distingués : les advergamings (jeux publicitaires), les edutainments (à vocation éducative), les edumarket games (utilisés pour la communication d'entreprise), les jeux engagés (ou détournés) et les jeux d'entraînement et de simulation.
* 93 Outre l'accès à la culture (visites de musées et de sites archéologiques par exemple), il pourrait s'agir de visites interactives dans des environnements historiques différents, permettant des sortes de voyages dans le temps.
*
94
•
Le numérique au service de la santé
, Catherine Procaccia
et Gérard Bapt, rapporteurs, Sénat n° 465
(2014-2015).
* 95 Un exemple récent concerne le dépistage du cancer du sein : http://www.numerama.com/sciences/176579-une-ia-sait-detecter-le-cancer-du-sein-presque-aussi-bien-quun-medecin.html
* 96 Ce processus physique, par lequel un polypeptide se replie dans sa structure tridimensionnelle caractéristique dans laquelle il est fonctionnel, est important en ce que de nombreuses maladies, en particulioer les maladies « neurodégénératives », sont considérées comme résultant d'une accumulation de protéines « mal repliées ».
* 97 Les raisonnements formels de Prolog ont été enrichis de la méthode de programmation par contraintes.
* 98 Les réseaux de neurones artificiels sont dans ce cas couplés aux méthodes d'apprentissage profond.
* 99 Ce programme a appris à jouer au jeu de Go en combinant apprentissage profond et apprentissage par renforcement.
* 100 L'efficacité est avérée pour le traitement automatique du langage naturel, la reconnaissance automatique de la parole, la reconnaissance audio, la bio-informatique ou, encore, la vision par ordinateur.
* 101 Cf. http://www.volle.com/ulb/021116/textes/intelligence.htm