







B. DES DONNÉES EXPLOITABLES TOUTEFOIS ENCORE INSUFFISANTES
1. Favoriser l'usage des données en améliorant leur « découvrabilité »
En dépit de leur ouverture, certaines données environnementales sont parfois peu utilisées en raison de leur caractère difficilement exploitable ou parce qu'elles ne suscitent pas l'intérêt escompté. La multiplicité des sources peut en outre rendre difficilement identifiables les données de référence, et par conséquent entraver leur « découvrabilité » selon l'expression de l'Écolab.
La qualité des métadonnées, qui permettent d'organiser les données et d'en faciliter l'utilisation, est également pointée, leur fréquence de mise à jour et leur granularité (le niveau de détail fourni) n'étant pas toujours adaptées aux usages.
Les améliorations à apporter à l'open data en matière environnementale
Parmi les pistes d'amélioration, la recherche d'une meilleure animation de la communauté open data, en France comme entre États membres européens, fait partie des axes identifiés, tout comme l'amélioration de la qualité des métadonnées ou encore de la couverture du catalogue du portail national.
Avancer sur le référencement des données environnementales
Si le foisonnement des données permet un maillage thématique et territorial bienvenu, un meilleur référencement de cet ensemble hétérogène apparaît nécessaire pour garantir sa lisibilité.
Dans la sphère étatique, un travail de centralisation des données produites par les services de l'État (DDT, DREAL,...) et les opérateurs est mené avec l'objectif de recenser et classer l'ensemble de celles relatives à la transition écologique et énergétique. Porté par l'équipe en charge de data.gouv.fr en collaboration avec le Commissariat général au développement durable (CGDD) et l'Écolab, le projet « Écosphères » vise à faciliter la recherche, la découverte et l'exploitation des données environnementales.
Dans une logique de développement de communs numériques, le portail et catalogue ecologie.data.gouv.fr propose une base technique réutilisable pour la création de portails thématiques de données. Plusieurs portails, dont celui relatif aux données de Météo-France, pourront ainsi s'appuyer sur le même code open source.
Passer d'une logique d'offre à une logique d'usage
Avec cette structuration de l'espace de la donnée, l'Écolab entend favoriser l'appropriation des données à des fins de transition écologique afin qu'elle devienne plus massive et systématique.
Dans ce contexte, les opérateurs de l'État sont invités à renforcer la qualité des données rendues disponibles, avec des exigences inscrites dans leur plan de charge. À titre d'exemple, le Cerema s'était donné comme objectif, dans le cadre de son contrat d'objectifs et de performance, de structurer d'ici fin 2024 des jeux de données de référence dans l'ensemble de ses domaines d'activité. Il apparaît indispensable d'encourager l'ensemble des acteurs concernés à approfondir les efforts réalisés en la matière.
Axe n° 1 : poursuivre les efforts visant à structurer les jeux de données en matière environnementale et améliorer leur référencement
Au terme de ce travail approfondi d'agrégation et d'interopérabilité, cette masse de données se verra dotée d'une « dimension d'infrastructure immatérielle comparable aux infrastructures physiques comme les réseaux de télécommunications »60(*).
2. Une connaissance encore lacunaire de certains éléments de notre environnement
Malgré la richesse et les efforts de structuration des données disponibles, certaines « briques » de notre environnement font encore l'objet d'une connaissance lacunaire, soit en raison de l'imperfection du système de recueil des informations, soit parce que la connaissance de ces éléments reste dans les mains d'acteurs privés.
a) Les données du sous-sol : un point faible du champ de vision
Une connaissance approfondie et fiable du sous-sol est nécessaire à une meilleure utilisation des ressources (eau, énergie, minéraux, métaux), à l'adaptation aux conséquences du changement climatique et à la gestion des risques naturels dans l'aménagement du territoire. Or le BRGM insiste sur l'incertitude dont est affectée la connaissance de cet élément essentiel de l'environnement et les données que l'on y acquiert.
Pour l'opérateur, il importe d'arriver à comprendre les incertitudes existantes et d'en tenir compte dans la chaîne de transformation de la donnée, en particulier lorsque cette chaîne comporte des traitements reposant sur des techniques d'IA.
La banque du sous-sol : des informations encore parcellaires et éparses
L'ensemble des données relatives aux ouvrages souterrains (forages, sondages, puits et sources) sont collectées et conservées dans la « banque du sous-sol » (BSS) gérée par le BRGM.
Bien que cette base de données fournisse des informations sur plus de 700 000 ouvrages et travaux souterrains réalisés depuis plus d'un siècle, les données relatives au sous-sol restent fragmentaires, contrairement à la connaissance de la géologie de surface qui fait l'objet de nombreuses cartes géologiques.
Or en pratique, les renseignements sur le sous-sol ne manquent pas et ils constituent un capital important pour l'environnement et la connaissance géologique. Ces données sont mises à jour à l'occasion de découvertes et d'exploitations de ressources naturelles enfouies (eau, pétrole, ressources minières), d'opérations de géotechnique (travaux d'infrastructure et d'aménagement), d'études de géothermie et de recherches scientifiques sur les phénomènes géologiques.
Afin de tirer parti des possibilités offertes par l'IA, l'enjeu est de pouvoir accéder à ces données, en quantité et en qualité suffisantes, pour le bon fonctionnement des méthodes d'apprentissage.
Pour répondre à ces difficultés, le BRGM participe, dans le cadre d'une approche collective, au Consortium industrie et recherche pour l'optimisation et la quantification d'incertitude pour les données onéreuses (CIROQUO)61(*).
L'établissement insiste sur les conditions concrètes qui doivent être réunies pour lui permettre de progresser dans la mise à disposition de données sur le sous-sol, parmi lesquelles :
- l'utilisation d'un système d'information scientifique d'établissement adapté ;
- l'emploi de données FAIR utilisant les standards internationaux62(*) ;
- l'accès aux données produites par d'autres acteurs académiques, collectivités territoriales et entreprises privées au travers d'e-infrastructures et de portail d'accès aux données ;
- et la possibilité de se référer à un cadre juridique clair pour l'accès et l'utilisation de ces données.
b) Les données d'intérêt général détenues par les acteurs privés
Si les données publiques sont régies par un principe d'ouverture par défaut, ce n'est généralement pas le cas des données privées. Celles-ci ne sont ouvertes que ponctuellement, le plus souvent dans le cadre d'approches sectorielles et au titre des « données d'intérêt général » comme le prévoit la loi pour une République numérique63(*).
La notion de « données d'intérêt général » : une approche très globale
Introduit par la loi pour une République numérique de 2016, le terme de « données d'intérêt général » s'entend de « données qui sont de nature privée mais dont la publication peut se justifier en raison de leur intérêt pour améliorer les politiques publiques ».
Cette définition peut faire référence aux données collectées ou produites dans le cadre d'une concession de service public et qui présentent un intérêt économique, social, sanitaire ou environnemental, mais elle ne vise pas les données environnementales dans leur ensemble.
Or certains acteurs privés possèdent des informations qui peuvent s'avérer précieuses pour faire avancer la connaissance de l'environnement, pour prévenir une situation de crise ou dans certains cas d'urgence.
Il peut s'agir de données personnelles, portant par exemple sur la consommation d'eau, d'énergie ou encore la production de déchets ménagers, ces données étant parfois produites par des objets connectés (capteurs, smartphones). Il peut également s'agir de données environnementales non publiques mais financées par des acteurs publics telles que les informations recueillies par les opérateurs de services urbains ou par les agences d'aménagement et d'urbanisme.
Cela peut enfin concerner des données privées qui peuvent se révéler d'intérêt général dans certaines situations, en particulier celles disponibles sur les réseaux sociaux en situation de crise.
Dans le cadre du projet « RéSoCIO », le BRGM a étudié la possibilité de traiter de manière automatique les éléments de langage et les données spatiales lors de crises liées à des risques naturels. Le dispositif mis au point permet de localiser et d'évaluer les impacts, en quelques secondes, à partir de messages laissés sur des réseaux sociaux.
La réussite de ce type de projet suppose une pleine coopération des réseaux sociaux concernés. Dans le cas de RéSoCIO, l'évolution des conditions d'accès aux données a malheureusement écarté les perspectives d'application opérationnelle.
Le projet « RéSoCIO » : utiliser l'IA en cas de catastrophe naturelle pour faciliter le traitement d'informations de terrain issues des réseaux sociaux
Mené par une équipe interdisciplinaire constituée du BRGM, de l'IMT Mines Albi, de l'Université Paris-Dauphine et de la société Predict-Services, le projet « RéSoCIO » (réseaux sociaux en situation de catastrophe naturelle, interprétation opérationnelle) a démarré en 2021 pour quatre ans et avec le soutien de l'Agence nationale de la recherche (ANR)64(*).
Il concernait la gestion des catastrophes dites « à cinétique très rapide » comme les crues éclair, les boues torrentielles ou encore les séismes. L'objectif était d'exploiter grâce à l'IA les informations de terrain publiées sur les réseaux sociaux par les sinistrés et les témoins directs afin de permettre aux acteurs de la gestion de crise (préfectures, mairies, services de secours...) d'améliorer leur connaissance de la situation (origine, intensité, ampleur des pertes, évolutions possibles) et la prise de décision.
La géolocalisation à partir de tweets
Un usage intensif des réseaux sociaux est souvent observé après la survenue de catastrophes naturelles, comme par exemple lors du séisme de Cholet en 2019. Dans ces situations, l'IA se présente comme un atout majeur pour identifier les messages utiles parmi les millions de « posts » envoyés chaque minute, et les analyser pratiquement en temps réel.
Le BRGM a élaboré un algorithme qui regroupe les tweets selon leur proximité à la fois spatiale et temporelle. S'agissant du séisme survenu à Cholet en 2019, les contours des tweets ainsi regroupés délimitent avec une relative précision la zone de perception du séisme qui couvre une grande partie de l'Ouest de la France.
Affichage « brut » de la densité de tweets captés à la suite au séisme de Cholet du 21 juin 2019 (à gauche) et regroupement automatique comparé à la zone de perception du séisme (à droite)
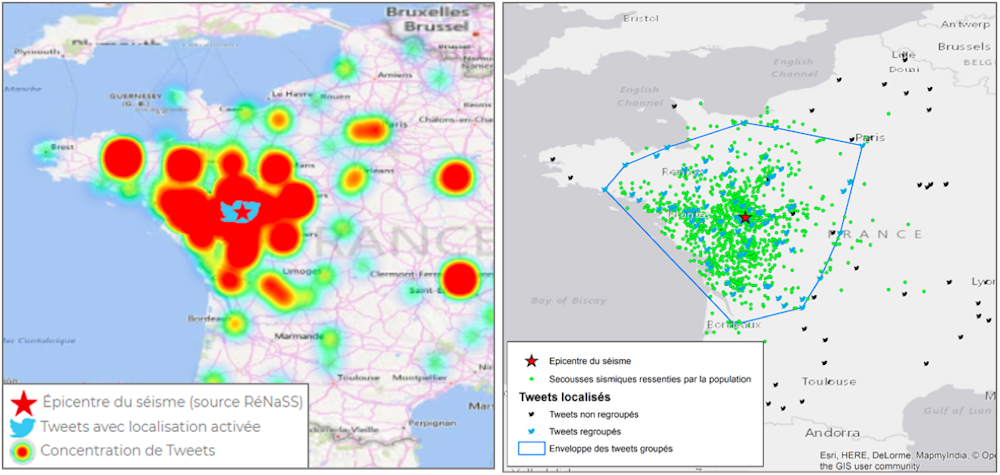
Source : BRGM
Une IA entraînée sur les données de Twitter
L'utilisation du réseau social Twitter (devenu X) a été privilégiée en raison du nombre important de ses utilisateurs actifs et du caractère concis des messages, mais aussi parce que ce réseau proposait une interface de programmation d'application (API) gratuite, permettant d'automatiser des collectes sur ses données.
Cette API a été utilisée par le BRGM pour développer une plateforme dédiée à l'analyse de tweets en cas de catastrophes naturelles65(*). Chaque message textuel faisait ainsi l'objet d'un triple enrichissement visant à :
- évaluer sa pertinence pour les acteurs de la gestion de crise ;
- repérer et géolocaliser les informations de lieux mentionnées pour les représenter sur une carte ;
- classer l'information par catégories d'intérêt, par exemple pour filtrer les messages signalant des dommages, ceux issus de témoins directs, etc.
Dans le cadre d'un apprentissage supervisé, l'entraînement a d'abord été réalisé sur des données dites « froides » (tweets sélectionnés attentivement au cours de crises passées et annotés). En ajustant les modèles prédictifs ainsi constitués, l'équipe les a ensuite utilisés pour l'analyse de données « chaudes », c'est-à-dire des tweets captés en temps réel.
Des données de moins en moins accessibles, entravant la conduite efficace du projet et, plus généralement, celle de la recherche appliquée
Jusqu'à début 2023, Twitter permettait à chacun d'utiliser une partie de ses données gratuitement, comme par exemple à travers des applications tierces comme TweetDeck. Depuis son rachat par Elon Musk et l'évolution de son modèle économique, le réseau social, devenu X, a supprimé son API gratuite pour la remplacer par des solutions onéreuses et désormais rédhibitoires pour les recherches académiques.
Cette évolution a soudainement rendu inutilisables les modèles d'analyse de tweets développés par l'équipe de recherche tout en démobilisant les acteurs associés (sapeurs-pompiers, services municipaux, volontaires) en éloignant la perspective d'une application concrète des travaux.
Parallèlement, l'irruption des grands modèles de langage (LLM), capables de construire des modèles prédictifs efficients à partir de quantités limitées de données étiquetées, a remis en cause la méthode de travail initialement retenue.
L'ensemble de ces éléments a mis un coup d'arrêt au projet dont il avait été envisagé l'extension à d'autres risques naturels tels que les tempêtes et les cyclones.
Dans ces conditions, une réflexion est à mener sur l'accès des chercheurs et des développeurs d'outils présentant un intérêt général aux données des réseaux sociaux. Si une voix forte et concordante doit se faire entendre auprès des grandes plateformes, l'approche doit être équilibrée pour éviter les éventuelles entraves à la concurrence ou les atteintes aux intérêts de la population.
L'exemple du projet « RéSoCIO » pose avec une grande acuité la question de savoir comment inciter les acteurs privés à partager leurs données d'intérêt général. Cette problématique n'est pas nouvelle. Le rapport « Villani » appelait déjà de ses voeux l'ouverture des données détenues par les acteurs privés dans le domaine de l'environnement à des fins de recherche ou d'intérêt général.
Selon Laurent Cytermann en 2018, « les données d'intérêt général peuvent être définies comme les données dont l'ouverture est justifiée par un motif d'intérêt général, soit en raison du lien entre la personne qui les contrôle et une personne publique, soit en raison de la nature des données elles-mêmes »66(*).
Dans un avis de juillet 2020, le Conseil national du numérique envisage une ouverture plus large de ces données en y incluant celles produites par les acteurs privés sans rattachement avec la puissance publique67(*).
Sans porter atteinte à la protection des données personnelles et à la propriété intellectuelle, la réflexion sur les conditions dans lesquelles la notion d'intérêt général pourrait être utilisée pour pousser les acteurs privés à les partager dans des conditions précises, en particulier en cas d'urgence pendant une crise, doit ainsi se poursuivre. Des modèles et des clauses types pourraient être prévus.
Ceci implique que ces acteurs privés trouvent un intérêt à ce partage, en termes d'image et de réputation ou d'ouverture à de nouvelles collaborations avec d'autres acteurs par exemple.
Axe n° 2 : inciter les acteurs privés à partager leurs données d'intérêt général, en particulier pour la recherche académique et dans les situations d'urgence
Cette incitation au partage des données peut aussi passer par des expérimentations dans des environnements d'essai (« bacs à sable »). Il s'agit d'essais pilotes permettant d'évaluer l'intérêt potentiel de la donnée pour des situations nouvelles dans lesquelles un service innovant pourrait être utilisé.
* 60 Avis du Conseil national du numérique, Faire des données environnementales des données d'intérêt général, juillet 2020.
* 61 Porté par l'École Centrale de Lyon et coanimé avec l'IFPEN (IFP Énergies nouvelles), ce consortium réunit des partenaires académiques et des structures de recherche technologique. Son objectif est de faire avancer la réflexion sur la résolution des problèmes liés à l'utilisation de simulateurs numériques. Les difficultés sont liées à la question de la transposition des codes, c'est-à-dire la question de savoir comment passer à une grande échelle lorsque des simulations ne sont possibles qu'à une petite échelle ou encore à la façon de prendre en compte les incertitudes qui affectent le résultat des simulations. Les travaux du consortium entendent se concentrer sur la simulation numérique tout en tenant compte des développements du machine learning.
* 62 Par exemple, l'OGC (Open Geospatial Consortium) est un consortium international pour développer et promouvoir des standards ouverts, afin de garantir la normalisation et l'interopérabilité des contenus dans les domaines de la géomatique et de l'information géographique.
* 63 Loi n° 2016-1321 du 7 octobre 2016 pour une République numérique.
* 64 Appel à projets générique 2020.
* 65 SURICATE-Nat, qui assure en continu la collecte et l'analyse des tweets liés aux phénomènes de séisme et d'inondation.
* 66 Laurent Cytermann, « Le partage des données, un enjeu d'intérêt général à l'ère de l'intelligence artificielle », Revue des affaires européennes, n° 1, 2018.
* 67 Avis du Conseil national du numérique, Faire des données environnementales des données d'intérêt général, juillet 2020.